def __init__(
self,
redis_key=None,
min_task_count=1,
check_task_interval=5,
thread_count=None,
begin_callback=None,
end_callback=None,
delete_keys=(),
keep_alive=None,
auto_start_requests=None,
send_run_time=False,
batch_interval=0,
wait_lock=True
):
"""
@param redis_key: 任务等数据存放在redis中的key前缀
@param min_task_count: 任务队列中最少任务数, 少于这个数量才会添加任务,默认1。start_monitor_task 模式下生效
@param check_task_interval: 检查是否还有任务的时间间隔;默认5秒
@param thread_count: 线程数,默认为配置文件中的线程数
@param begin_callback: 爬虫开始回调函数
@param end_callback: 爬虫结束回调函数
@param delete_keys: 爬虫启动时删除的key,类型: 元组/bool/string。 支持正则; 常用于清空任务队列,否则重启时会断点续爬
@param keep_alive: 爬虫是否常驻
@param auto_start_requests: 爬虫是否自动添加任务
@param send_run_time: 发送运行时间
@param batch_interval: 抓取时间间隔 默认为0 天为单位 多次启动时,只有当前时间与第一次抓取结束的时间间隔大于指定的时间间隔时,爬虫才启动
@param wait_lock: 下发任务时否等待锁,若不等待锁,可能会存在多进程同时在下发一样的任务,因此分布式环境下请将该值设置True
"""
下面介绍下理解起来可能有疑惑的参数
redis_key为redis中存储任务等信息的key前缀,如redis_key="feapder:spider_test", 则redis中会生成如下
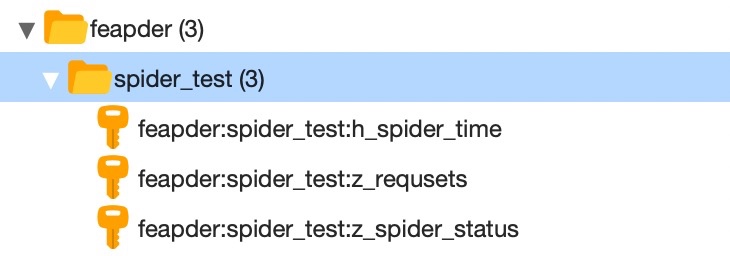
key的命名方式为配置文件中定义的
# 任务表模版
TAB_REQUESTS = "{redis_key}:z_requsets"
# 任务失败模板
TAB_FAILED_REQUESTS = "{redis_key}:z_failed_requsets"
# 爬虫状态表模版
TAB_SPIDER_STATUS = "{redis_key}:z_spider_status"
# item 表模版
TAB_ITEM = "{redis_key}:s_{item_name}"
# 爬虫时间记录表
TAB_SPIDER_TIME = "{redis_key}:h_spider_time"
这个参数用于控制最小任务数的,少于这个数量再下发任务,防止redis中堆积任务太多,内存撑爆,通常用于从数据库中取任务,下发。
此参数需要使用start_monitor_task方式才会生效,示例如下:
import feapder
from feapder.db.mysqldb import MysqlDB
class SpiderTest(feapder.Spider):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.db = MysqlDB()
def start_requests(self):
sql = "select url from feapder_test where state = 0 limit 1000"
result = self.db.find(sql)
for url, in result:
yield feapder.Request(url)
def parser(self, request, response):
print(response)
if __name__ == "__main__":
spider = SpiderTest(
redis_key="feapder:spider_test", min_task_count=100
)
# 监控任务,若任务数小于min_task_count,则调用start_requests下发一批,注start_requests产生的任务会一次下发完,比如本例,会一次下发1000个任务,然后任务队列中少于100条任务时,再下发1000条
spider.start_monitor_task()
# 采集
# spider.start()spider.start_monitor_task() 与 spider.start() 分开运行,属于master、worker两种进程
通常在开发阶段使用,如想清空任务队列重新抓取,或防止由于任务防丢策略导致爬虫需等待10分钟才能取到任务的情况。使用场景见运行问题
delete_keys 接收类型为tuple/bool/string,支持正则,拿以下的key举例
删除feapder:spider_test_z_requests 可写为 delete_keys="*z_requests"
删除全部可写为delete_keys="*"
用于spider.start_monitor_task() 与 spider.start() 这种master、worker模式。
keep_alive=True时,爬虫做完任务后不会退出,继续等待任务。
是否将运行时间作为报警信息发送
设置每次采集的时间间隔,如我们设置7天,当爬虫正常结束后,7天内我们二次运行爬虫时会自动退出,不执行采集逻辑
def spider_test():
spider = test_spider.TestSpider(redis_key="feapder:test_spider", batch_interval=7)
spider.start()
运行:
上次运行结束时间为 2021-03-15 14:42:31 与当前时间间隔 为 3秒, 小于规定的抓取时间间隔 7天。爬虫不执行,退出~
Spider继承至BaseParser,并且BaseParser是对开发者暴露的常用方法接口,因此推荐先看BaseParser,Spider方法如下:
下发及监控任务,与keep_alive参数配合使用,用于常驻进程的爬虫
使用:
spider = test_spider.TestSpider(redis_key="feapder:test_spider", keep_alive=True)
# 下发及监控任务
spider.start_monitor_task()
# 采集(进程常驻)
# spider.start()
spider.start_monitor_task() 与 spider.start() 分开运行,属于master、worker两种进程
Spider爬虫支持任务防丢,断点续爬,实现原理如下:
Spider利用了redis有序集合来存储任务,有序集合有个分数,爬虫取任务时,只取小于当前时间戳分数的任务,同时将任务分数修改为当前时间戳+10分钟,(这个取任务与改分数是原子性的操作)。当任务做完时,且数据已入库后,再主动将任务删除。
目的:将取到的任务分数修改成10分钟后,可防止其他爬虫节点取到同样的任务,同时当爬虫意外退出后,任务也不会丢失,10分钟后还可以取到。
10分钟是可配置的,为配置文件中的REQUEST_LOST_TIMEOUT参数
任务请求失败或解析函数抛出异常时,会自动重试,默认重试次数为100次,可通过配置文件SPIDER_MAX_RETRY_TIMES参数修改。当任务超过最大重试次数时,默认会将失败的任务存储到Redis的{redis_key}:z_failed_requsets里,供人工排查。
相关配置为:
# 每个请求最大重试次数
SPIDER_MAX_RETRY_TIMES = 100
# 重新尝试失败的requests 当requests重试次数超过允许的最大重试次数算失败
RETRY_FAILED_REQUESTS = False
# 保存失败的request
SAVE_FAILED_REQUEST = True
# 任务失败数 超过WARNING_FAILED_COUNT则报警
WARNING_FAILED_COUNT = 1000当RETRY_FAILED_REQUESTS=True时,爬虫再次启动时会将失败的任务重新下发到任务队列中,重新抓取
支持任务去重和数据去重,任务默认是临时去重,去重库保留1个月,即只去重1个月内的任务,数据是永久去重。默认去重是关闭的,相关配置为:
ITEM_FILTER_ENABLE = False # item 去重
REQUEST_FILTER_ENABLE = False # request 去重
修改默认去重库:
from feapder.buffer.request_buffer import RequestBuffer
from feapder.buffer.item_buffer import ItemBuffer
from feapder.dedup import Dedup
RequestBuffer.dedup = Dedup(filter_type=Dedup.MemoryFilter)
ItemBuffer.dedup = Dedup(filter_type=Dedup.MemoryFilter)
RequestBuffer 为任务入库前缓冲的buffer,ItemBuffer为数据入库前缓冲的buffer
关于去重库详情见:海量数据去重
与爬虫采集速度的相关配置为:
# 爬虫相关
# COLLECTOR
COLLECTOR_SLEEP_TIME = 1 # 从任务队列中获取任务到内存队列的间隔
COLLECTOR_TASK_COUNT = 10 # 每次获取任务数量
# SPIDER
SPIDER_THREAD_COUNT = 1 # 爬虫并发数
SPIDER_SLEEP_TIME = 0 # 下载时间间隔(解析完一个response后休眠时间)
SPIDER_MAX_RETRY_TIMES = 100 # 每个请求最大重试次数COLLECTOR 为从任务队列中取任务到内存队列的线程,SPIDER为实际采集的线程
COLLECTOR_TASK_COUNT 建议 >= SPIDER_THREAD_COUNT, 这样每个线程的爬虫才有任务可做。但COLLECTOR_TASK_COUNT不建议过大,不然分布式时,一个池子里的任务都被节点A取走了,其他节点取不到任务了。
更多配置,详见配置文件