#}
+ {# 您好,我是机器人小明,感谢您使用本系统。
#}
+ {# 假设您是一位在校大学生,正在学习计算机相关的专业,并且热爱计算机。
#}
+ {#
#}
+ {# #}
+ {# {{ g.name }}
+{{ g.detail }}
+ +
+
+  +
+
+
+
+
+
+
+
+
![]() +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
持续维护的新浪微博采集工具🚀🚀🚀
+ + + +## 项目特色 + +- 基于weibo.com的新版API构建,拥有最丰富的字段信息 +- 多种采集模式,包含微博用户,推文,粉丝,关注,转发,评论,关键词搜索 +- 核心代码仅100行,代码可读性高,可快速按需进行定制化改造 + +## 快速开始 + +### 拉取&&安装 + +```bash +git clone git@github.com:nghuyong/WeiboSpider.git --depth 1 --no-single-branch +cd WeiboSpider +pip install -r requirements.txt +``` + +### 替换Cookie + +访问[https://weibo.com/](https://weibo.com/), 登陆账号,打开浏览器的开发者模式,再次刷新 + + + +复制`weibo.com`数据包,network中的cookie值。编辑`weibospider/cookie.txt`并替换成刚刚复制的Cookie + +### 添加代理IP(可选) + +重写[fetch_proxy](./weibospider/middlewares.py#6L) +方法,该方法需要返回一个代理ip,具体参考[这里](https://github.com/nghuyong/WeiboSpider/issues/124#issuecomment-654335439) + +## 运行程序 + +根据自己实际需要重写`./weibospider/spiders/*`中的`start_requests`函数 + +采集的数据存在`output`文件中,命名为`{spider.name}_{datetime}.jsonl` + +### 用户信息采集 + +```bash +cd weibospider +python run_spider.py user +``` + +```json +{ + "crawl_time": 1666863485, + "_id": "1749127163", + "avatar_hd": "https://tvax4.sinaimg.cn/crop.0.0.1080.1080.1024/001Un9Srly8h3fpj11yjyj60u00u0q7f02.jpg?KID=imgbed,tva&Expires=1666874283&ssig=a%2FMfgFzvRo", + "nick_name": "雷军", + "verified": true, + "description": "小米董事长,金山软件董事长。业余爱好是天使投资。", + "followers_count": 22756103, + "friends_count": 1373, + "statuses_count": 14923, + "gender": "m", + "location": "北京 海淀区", + "mbrank": 7, + "mbtype": 12, + "verified_type": 0, + "verified_reason": "小米创办人,董事长兼CEO;金山软件董事长;天使投资人。", + "birthday": "", + "created_at": "2010-05-31 23:07:59", + "desc_text": "小米创办人,董事长兼CEO;金山软件董事长;天使投资人。", + "ip_location": "IP属地:北京", + "sunshine_credit": "信用极好", + "label_desc": [ + "V指数 财经 75.30分", + "热门财经博主 数据飙升", + "昨日发博3,阅读数100万+,互动数1.9万", + "视频累计播放量9819.3万", + "群友 3132" + ], + "company": "金山软件", + "education": { + "school": "武汉大学" + } +} +``` + +### 用户粉丝列表采集 + +```bash +python run_spider.py fan +``` + +```json +{ + "crawl_time": 1666863563, + "_id": "1087770692_5968044974", + "follower_id": "1087770692", + "fan_info": { + "_id": "5968044974", + "avatar_hd": "https://tvax1.sinaimg.cn/default/images/default_avatar_male_180.gif?KID=imgbed,tva&Expires=1666874363&ssig=UuzaeK437R", + "nick_name": "用户5968044974", + "verified": false, + "description": "", + "followers_count": 0, + "friends_count": 195, + "statuses_count": 9, + "gender": "m", + "location": "其他", + "mbrank": 0, + "mbtype": 0, + "credit_score": 80, + "created_at": "2016-06-25 22:30:13" + } +} +... +``` + +### 用户关注列表采集 + +```bash +python run_spider.py follow +``` + +```json +{ + "crawl_time": 1666863679, + "_id": "1087770692_7083568088", + "fan_id": "1087770692", + "follower_info": { + "_id": "7083568088", + "avatar_hd": "https://tvax4.sinaimg.cn/crop.0.0.1080.1080.1024/007JnVEcly8gyqd9jadjlj30u00u0gpn.jpg?KID=imgbed,tva&Expires=1666874479&ssig=9zhfeMPLzr", + "nick_name": "蒋昀霖", + "verified": true, + "description": "工作请联系:lijialun@kpictures.cn", + "followers_count": 329216, + "friends_count": 58, + "statuses_count": 342, + "gender": "m", + "location": "北京", + "mbrank": 6, + "mbtype": 12, + "credit_score": 80, + "created_at": "2019-04-17 16:25:43", + "verified_type": 0, + "verified_reason": "东申未来 演员" + } +} +... +``` + +### 用户的微博采集 + +```bash +python run_spider.py tweet +``` + +```json +{ + "crawl_time": 1666864583, + "_id": "4762810834227120", + "mblogid": "LqlZNhJFm", + "created_at": "2022-04-27 10:20:54", + "geo": null, + "ip_location": null, + "reposts_count": 1907, + "comments_count": 1924, + "attitudes_count": 12169, + "source": "三星Galaxy S22 Ultra", + "content": "生于乱世纵横四海,义之所在不计生死,孤勇者陈恭一生当如是。#风起陇西今日开播# #风起陇西# 今晚,恭候你!", + "pic_urls": [], + "pic_num": 0, + "video": "http://f.video.weibocdn.com/o0/CmQEWK1ylx07VAm0nrxe01041200YDIc0E010.mp4?label=mp4_720p&template=1280x720.25.0&ori=0&ps=1CwnkDw1GXwCQx&Expires=1666868183&ssig=RlIeOt286i&KID=unistore,video", + "url": "https://weibo.com/1087770692/LqlZNhJFm" +} +... +``` + +### 微博评论采集 + +```bash +python run_spider.py comment +``` + +```json +{ + "crawl_time": 1666863805, + "_id": 4826279188108038, + "created_at": "2022-10-19 13:41:29", + "like_counts": 1, + "ip_location": "来自河南", + "content": "五周年快乐呀,请坤哥哥继续保持这份热爱,奔赴下一场山海", + "comment_user": { + "_id": "2380967841", + "avatar_hd": "https://tvax4.sinaimg.cn/crop.0.0.888.888.1024/002B8iv7ly8gv647ipgxvj60oo0oojtk02.jpg?KID=imgbed,tva&Expires=1666874604&ssig=%2FdGaaIRkhf", + "nick_name": "流年执念的二瓜娇", + "verified": false, + "description": "蓝桉已遇释怀鸟,不爱万物唯爱你。", + "followers_count": 238, + "friends_count": 1655, + "statuses_count": 12546, + "gender": "f", + "location": "河南", + "mbrank": 6, + "mbtype": 11 + } +} +... +``` + +### 微博转发采集 + +```bash +python run_spider.py repost +``` + +```json +{ + "_id": "4826312651310475", + "mblogid": "Mb2vL5uUH", + "created_at": "2022-10-19 15:54:27", + "geo": null, + "ip_location": "发布于 德国", + "reposts_count": 0, + "comments_count": 0, + "attitudes_count": 0, + "source": "iPhone客户端", + "content": "共享[鼓掌][太开心][鼓掌]五周年快乐!//@陈坤:#山下学堂五周年# 五年, 感谢同行。", + "pic_urls": [], + "pic_num": 0, + "user": { + "_id": "2717869081", + "avatar_hd": "https://tvax1.sinaimg.cn/crop.0.0.160.160.1024/a1ff6419ly8gz1xoq9oolj204g04g745.jpg?KID=imgbed,tva&Expires=1666876939&ssig=Cl93CLjdB%2F", + "nick_name": "YuFeeC", + "verified": false, + "mbrank": 0, + "mbtype": 0 + }, + "url": "https://weibo.com/2717869081/Mb2vL5uUH", + "crawl_time": 1666866139 +} +... +``` + +### 基于关键词的微博检索 + +```bash +python run_spider.py search +``` + +```json +{ + "crawl_time": 1666869049, + "keyword": "丽江", + "_id": "4829255386537989", + "mblogid": "Mch46rqPr", + "created_at": "2022-10-27 18:47:50", + "geo": { + "type": "Point", + "coordinates": [ + 26.962427, + 100.248299 + ], + "detail": { + "poiid": "B2094251D06FAAF44299", + "title": "山野文创旅拍圣地", + "type": "checkin", + "spot_type": "0" + } + }, + "ip_location": "发布于 云南", + "reposts_count": 0, + "comments_count": 0, + "attitudes_count": 1, + "source": "iPhone1314iPhone客户端", + "content": "丽江小漾日出\n推出户外移动餐桌\n接受私人定制\n让美食融入美景心情自然美丽了!\n#小众宝藏旅行地##超出片的艺术街区# ", + "pic_urls": [ + "https://wx1.sinaimg.cn/orj960/4b138405gy1h7k1a56c4oj234022onph", + "https://wx1.sinaimg.cn/orj960/4b138405gy1h7k19eb2kxj22ts1vvb2a", + "https://wx1.sinaimg.cn/orj960/4b138405gy1h7k1a0wzglj22ua1w7hdw", + "https://wx1.sinaimg.cn/orj960/4b138405gy1h7k19wsafnj231x21a7wj", + "https://wx1.sinaimg.cn/orj960/4b138405gy1h7k19jd1xkj22oh1sbkjo", + "https://wx1.sinaimg.cn/orj960/4b138405gy1h7k19mma74j22ru1ukx6q", + "https://wx1.sinaimg.cn/orj960/4b138405gy1h7k19tf1bfj234022oe85", + "https://wx1.sinaimg.cn/orj960/4b138405gy1h7k19pk37pj234022okjm", + "https://wx1.sinaimg.cn/orj960/4b138405gy1h7k19g6nzfj20wi0lo7my" + ], + "pic_num": 9, + "user": { + "_id": "1259570181", + "avatar_hd": "https://tvax1.sinaimg.cn/crop.0.0.1080.1080.1024/4b138405ly8gzfkfikyqvj20u00u0ag1.jpg?KID=imgbed,tva&Expires=1666879848&ssig=6PUDG5RonQ", + "nick_name": "飞鸟与鱼", + "verified": true, + "mbrank": 7, + "mbtype": 12, + "verified_type": 0 + }, + "url": "https://weibo.com/1259570181/Mch46rqPr" +} +... +``` + +## 更新日志 + +- 2022.10: 添加IP归属地信息的采集,包括用户数据,微博数据和微博评论数据 +- 2022.10: 基于weibo.com站点对项目进行重构 + +## 合作联系 + +- 已构建超大规模数据集WeiboCOV,可免费申请,包含2千万微博活跃用户以及6千万推文数据,参见[这里](https://github.com/nghuyong/weibo-public-opinion-datasets) +- 已构建一站式科研数据平台,涵盖Twitter,微博等诸多站点,点点鼠标即可进行数据采集与分析,参见[这里](https://yisukeyan.com/) diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/output/search_spider_20221029204111.jsonl" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/output/search_spider_20221029204111.jsonl" new file mode 100644 index 0000000..0d39f52 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/output/search_spider_20221029204111.jsonl" @@ -0,0 +1,5 @@ +{"_id": "4217503187934849", "mblogid": "G7lkWxidr", "created_at": "2018-03-14 16:03:00", "geo": null, "ip_location": null, "reposts_count": 0, "comments_count": 8, "attitudes_count": 9, "source": "前置双摄vivo X9s", "content": "#晚枫歌孟子坤烈火如歌#\n相煎何太急[微笑][微笑][微笑]\n别逼大家要找程序员来查ip地址。 ", "pic_urls": [], "pic_num": 0, "user": {"_id": "6378928531", "avatar_hd": "https://tvax3.sinaimg.cn/crop.0.0.996.996.1024/006XHkI3ly8gv6ppldahwj60ro0rojsj02.jpg?KID=imgbed,tva&Expires=1667058071&ssig=E7QYCEhr69", "nick_name": "罗兰_不爱麦架也爱你", "verified": true, "mbrank": 7, "mbtype": 12, "verified_type": 0}, "url": "https://weibo.com/6378928531/G7lkWxidr", "keyword": "程序员晚枫", "crawl_time": 1667047271} +{"_id": "4759749130718510", "mblogid": "Lp4lz30US", "created_at": "2022-04-18 23:34:47", "geo": null, "ip_location": null, "reposts_count": 1, "comments_count": 7, "attitudes_count": 3, "source": "程序员超话", "content": "#程序员[超话]# 晚枫老师,我在看您的视频学习python,其中关于Excel读取这一节,我按照您的代码写完之后,运行的时候总是出现这个问题,麻烦帮看一下怎么回事?谢谢@程序员晚枫 ", "pic_urls": ["https://wx1.sinaimg.cn/orj960/005SyqpGly1h1eap6j5uzj31hc0u0gw4"], "pic_num": 1, "user": {"_id": "5386790992", "avatar_hd": "https://tvax1.sinaimg.cn/crop.0.0.750.750.1024/005SyqpGly8goo7wa0iywj30ku0kuwfv.jpg?KID=imgbed,tva&Expires=1667058072&ssig=smmWkSKeih", "nick_name": "全时段体育", "verified": true, "mbrank": 4, "mbtype": 2, "verified_type": 0}, "url": "https://weibo.com/5386790992/Lp4lz30US", "keyword": "程序员晚枫", "crawl_time": 1667047272} +{"_id": "4760034112702900", "mblogid": "LpbLdbl9a", "created_at": "2022-04-19 18:27:12", "geo": null, "ip_location": null, "reposts_count": 0, "comments_count": 4, "attitudes_count": 0, "source": "iPhone客户端", "content": "用示例中代码做微信机器人,请问@程序员晚枫 大佬,为什么扫码登陆的时候提示下面的报错呢?\n视频看了两遍也没有看到代码报错或者权限报错的现状是什么样子?只能来这里发问了\n\nGetting uuid of QR code.\nDownloading QR code.\nPlease scan the QR code to log in.\nPlease press confirm on your phone ", "pic_urls": ["https://wx1.sinaimg.cn/orj960/56819c94ly1h1f792tjrcj21hc0u0gq4"], "pic_num": 1, "user": {"_id": "1451334804", "avatar_hd": "https://tvax2.sinaimg.cn/crop.0.0.1242.1242.1024/56819c94ly8fqlug3kdgxj20yi0yin15.jpg?KID=imgbed,tva&Expires=1667058073&ssig=sgRW3u1FBw", "nick_name": "圣瑞思大马修", "verified": false, "mbrank": 0, "mbtype": 0}, "url": "https://weibo.com/1451334804/LpbLdbl9a", "keyword": "程序员晚枫", "crawl_time": 1667047273} +{"_id": "4766165916713902", "mblogid": "LrLhdsaAK", "created_at": "2022-05-06 16:32:47", "geo": null, "ip_location": "发布于 江苏", "reposts_count": 0, "comments_count": 1, "attitudes_count": 0, "source": "新版微博 weibo.com", "content": "运行时报缺少这个,从哪里能添加到? @程序员晚枫 ", "pic_urls": ["https://wx1.sinaimg.cn/orj960/71b76a37gy1h1yroo1cgqj20oe03ggnz"], "pic_num": 1, "user": {"_id": "1907845687", "avatar_hd": "https://tva3.sinaimg.cn/crop.0.0.180.180.1024/71b76a37jw1e8qgp5bmzyj2050050aa8.jpg?KID=imgbed,tva&Expires=1667058075&ssig=oGsbWuIoSW", "nick_name": "南通瞿标", "verified": false, "mbrank": 0, "mbtype": 0}, "url": "https://weibo.com/1907845687/LrLhdsaAK", "keyword": "程序员晚枫", "crawl_time": 1667047275} +{"_id": "4801674139666097", "mblogid": "M0HydEyAN", "created_at": "2022-08-12 16:09:48", "geo": null, "ip_location": "发布于 广东", "reposts_count": 0, "comments_count": 0, "attitudes_count": 1, "source": "HUAWEI Mate 30", "content": "“着眼长远的职业生涯,你初入职场的这3年,更重要的在给公司创造价值的前提下,在公司里获得多少技术成长、提升行业认知、认识同行朋友,而不是挣多少钱。\n\n人在每个阶段都有不同的任务,有的人能一眼就看透事物的本质,而有的人一辈子也看不透,这两种人有着不同的命运。”\n\n出自创业选手@程序员晚枫 ", "pic_urls": [], "pic_num": 0, "user": {"_id": "5110333487", "avatar_hd": "https://tvax1.sinaimg.cn/crop.0.0.664.664.1024/005zQrbFly8g4sc3x22q8j30ig0ig0v1.jpg?KID=imgbed,tva&Expires=1667058076&ssig=FWmtPCpzDu", "nick_name": "万轻舟的微博", "verified": true, "mbrank": 2, "mbtype": 2, "verified_type": 0}, "url": "https://weibo.com/5110333487/M0HydEyAN", "keyword": "程序员晚枫", "crawl_time": 1667047276} diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/output/search_spider_20221029205945.jsonl" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/output/search_spider_20221029205945.jsonl" new file mode 100644 index 0000000..3bea047 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/output/search_spider_20221029205945.jsonl" @@ -0,0 +1,5 @@ +{"_id": "4217503187934849", "mblogid": "G7lkWxidr", "created_at": "2018-03-14 16:03:00", "geo": null, "ip_location": null, "reposts_count": 0, "comments_count": 8, "attitudes_count": 9, "source": "前置双摄vivo X9s", "content": "#晚枫歌孟子坤烈火如歌#\n相煎何太急[微笑][微笑][微笑]\n别逼大家要找程序员来查ip地址。 ", "pic_urls": [], "pic_num": 0, "user": {"_id": "6378928531", "avatar_hd": "https://tvax3.sinaimg.cn/crop.0.0.996.996.1024/006XHkI3ly8gv6ppldahwj60ro0rojsj02.jpg?KID=imgbed,tva&Expires=1667059185&ssig=quHciEQStV", "nick_name": "罗兰_不爱麦架也爱你", "verified": true, "mbrank": 7, "mbtype": 12, "verified_type": 0}, "url": "https://weibo.com/6378928531/G7lkWxidr", "keyword": "程序员晚枫", "crawl_time": 1667048385} +{"_id": "4759749130718510", "mblogid": "Lp4lz30US", "created_at": "2022-04-18 23:34:47", "geo": null, "ip_location": null, "reposts_count": 1, "comments_count": 7, "attitudes_count": 3, "source": "程序员超话", "content": "#程序员[超话]# 晚枫老师,我在看您的视频学习python,其中关于Excel读取这一节,我按照您的代码写完之后,运行的时候总是出现这个问题,麻烦帮看一下怎么回事?谢谢@程序员晚枫 ", "pic_urls": ["https://wx1.sinaimg.cn/orj960/005SyqpGly1h1eap6j5uzj31hc0u0gw4"], "pic_num": 1, "user": {"_id": "5386790992", "avatar_hd": "https://tvax1.sinaimg.cn/crop.0.0.750.750.1024/005SyqpGly8goo7wa0iywj30ku0kuwfv.jpg?KID=imgbed,tva&Expires=1667059186&ssig=HB2KWdPSEg", "nick_name": "全时段体育", "verified": true, "mbrank": 4, "mbtype": 2, "verified_type": 0}, "url": "https://weibo.com/5386790992/Lp4lz30US", "keyword": "程序员晚枫", "crawl_time": 1667048386} +{"_id": "4760034112702900", "mblogid": "LpbLdbl9a", "created_at": "2022-04-19 18:27:12", "geo": null, "ip_location": null, "reposts_count": 0, "comments_count": 4, "attitudes_count": 0, "source": "iPhone客户端", "content": "用示例中代码做微信机器人,请问@程序员晚枫 大佬,为什么扫码登陆的时候提示下面的报错呢?\n视频看了两遍也没有看到代码报错或者权限报错的现状是什么样子?只能来这里发问了\n\nGetting uuid of QR code.\nDownloading QR code.\nPlease scan the QR code to log in.\nPlease press confirm on your phone ", "pic_urls": ["https://wx1.sinaimg.cn/orj960/56819c94ly1h1f792tjrcj21hc0u0gq4"], "pic_num": 1, "user": {"_id": "1451334804", "avatar_hd": "https://tvax2.sinaimg.cn/crop.0.0.1242.1242.1024/56819c94ly8fqlug3kdgxj20yi0yin15.jpg?KID=imgbed,tva&Expires=1667059187&ssig=O56OoVYAYs", "nick_name": "圣瑞思大马修", "verified": false, "mbrank": 0, "mbtype": 0}, "url": "https://weibo.com/1451334804/LpbLdbl9a", "keyword": "程序员晚枫", "crawl_time": 1667048387} +{"_id": "4766165916713902", "mblogid": "LrLhdsaAK", "created_at": "2022-05-06 16:32:47", "geo": null, "ip_location": "发布于 江苏", "reposts_count": 0, "comments_count": 1, "attitudes_count": 0, "source": "新版微博 weibo.com", "content": "运行时报缺少这个,从哪里能添加到? @程序员晚枫 ", "pic_urls": ["https://wx1.sinaimg.cn/orj960/71b76a37gy1h1yroo1cgqj20oe03ggnz"], "pic_num": 1, "user": {"_id": "1907845687", "avatar_hd": "https://tva3.sinaimg.cn/crop.0.0.180.180.1024/71b76a37jw1e8qgp5bmzyj2050050aa8.jpg?KID=imgbed,tva&Expires=1667059188&ssig=A3yS3FaOPW", "nick_name": "南通瞿标", "verified": false, "mbrank": 0, "mbtype": 0}, "url": "https://weibo.com/1907845687/LrLhdsaAK", "keyword": "程序员晚枫", "crawl_time": 1667048388} +{"_id": "4801674139666097", "mblogid": "M0HydEyAN", "created_at": "2022-08-12 16:09:48", "geo": null, "ip_location": "发布于 广东", "reposts_count": 0, "comments_count": 0, "attitudes_count": 1, "source": "HUAWEI Mate 30", "content": "“着眼长远的职业生涯,你初入职场的这3年,更重要的在给公司创造价值的前提下,在公司里获得多少技术成长、提升行业认知、认识同行朋友,而不是挣多少钱。\n\n人在每个阶段都有不同的任务,有的人能一眼就看透事物的本质,而有的人一辈子也看不透,这两种人有着不同的命运。”\n\n出自创业选手@程序员晚枫 ", "pic_urls": [], "pic_num": 0, "user": {"_id": "5110333487", "avatar_hd": "https://tvax1.sinaimg.cn/crop.0.0.664.664.1024/005zQrbFly8g4sc3x22q8j30ig0ig0v1.jpg?KID=imgbed,tva&Expires=1667059190&ssig=lEy2YK13FG", "nick_name": "万轻舟的微博", "verified": true, "mbrank": 2, "mbtype": 2, "verified_type": 0}, "url": "https://weibo.com/5110333487/M0HydEyAN", "keyword": "程序员晚枫", "crawl_time": 1667048390} diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/output/user_spider_20221029203525.jsonl" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/output/user_spider_20221029203525.jsonl" new file mode 100644 index 0000000..3d9c608 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/output/user_spider_20221029203525.jsonl" @@ -0,0 +1 @@ +{"_id": "7726957925", "avatar_hd": "https://tvax1.sinaimg.cn/crop.0.0.600.600.1024/008qVwJDly8h2abcnv801j30go0gotbb.jpg?KID=imgbed,tva&Expires=1667057724&ssig=9ZXQZmHKrh", "nick_name": "程序员晚枫", "verified": false, "description": "法学院毕业的Python程序员,在重庆。", "followers_count": 170, "friends_count": 19, "statuses_count": 125, "gender": "m", "location": "重庆 渝中区", "mbrank": 0, "mbtype": 0, "birthday": "1995-08-17", "created_at": "2021-12-04 02:21:10", "desc_text": "", "ip_location": "IP属地:重庆", "sunshine_credit": "信用一般", "label_desc": ["视频累计播放量1.9万"], "education": {"school": "华南理工大学"}, "crawl_time": 1667046925} diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/requirements.txt" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/requirements.txt" new file mode 100644 index 0000000..142c380 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/requirements.txt" @@ -0,0 +1,2 @@ +Scrapy +python_dateutil \ No newline at end of file diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/cookie.txt" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/cookie.txt" new file mode 100644 index 0000000..63573ba --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/cookie.txt" @@ -0,0 +1 @@ +SINAGLOBAL=6523076323654.351.1650469799845; UOR=,,www.cuba.edu.cn; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WF8Yo_iE16HE9YvhIg6bX3A5JpX5KMhUgL.FoMNeoq4SKM4eo-2dJLoIEXLxKMLBKnL12zLxK-LB.2L12qLxK-L1K2L1KnLxKqL1K.L1-2LxKqL1--LB-zt; ULV=1667033555436:27:2:1:401979337155.11615.1667033555427:1666277183696; PC_TOKEN=00fcdec311; ALF=1698582421; SSOLoginState=1667046421; SCF=Ai46ajJHnMeCXyYLxUYg45dieMLnFK2EzRdspykP7lGrQ7_eb6V1XuQhtEdvmsRDhbVggqvZGV8z18jeRCJpiac.; SUB=_2A25OWWxGDeRhGeFJ6VQY9SnFyTmIHXVtL9qOrDV8PUNbmtAKLUalkW9NfEEEWWujgSWU-sbABnYlYbBl1FXqljG-; XSRF-TOKEN=C-dgymp22o-Spn8PoyB6EflV; WBPSESS=jHKxeYP8s9YopP7Ymn-kut4uuV-3GEHovaQ17tbsnNjlXrsov0jiNl7NLsW49Zwztp3fSr9w-_lrdWcsHH3kxQHp3kLAxmUZipdgjVPotofgvIqNTSgObeNPGrFhczsmRVLZgb4jqaeUGaVNazaDgA== \ No newline at end of file diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/middlewares.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/middlewares.py" new file mode 100644 index 0000000..79d6815 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/middlewares.py" @@ -0,0 +1,26 @@ +# encoding: utf-8 + + +class IPProxyMiddleware(object): + """ + 代理IP中间件 + """ + + @staticmethod + def fetch_proxy(): + """ + 获取一个代理IP + """ + # You need to rewrite this function if you want to add proxy pool + # the function should return an ip in the format of "ip:port" like "12.34.1.4:9090" + return None + + def process_request(self, request, spider): + """ + 将代理IP添加到request请求中 + """ + proxy_data = self.fetch_proxy() + if proxy_data: + current_proxy = f'http://{proxy_data}' + spider.logger.debug(f"current proxy:{current_proxy}") + request.meta['proxy'] = current_proxy diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/pipelines.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/pipelines.py" new file mode 100644 index 0000000..d4a0803 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/pipelines.py" @@ -0,0 +1,30 @@ +# -*- coding: utf-8 -*- +import datetime +import json +import os.path +import time + + +class JsonWriterPipeline(object): + """ + 写入json文件的pipline + """ + + def __init__(self): + self.file = None + if not os.path.exists('../output'): + os.mkdir('../output') + + def process_item(self, item, spider): + """ + 处理item + """ + if not self.file: + now = datetime.datetime.now() + file_name = spider.name + "_" + now.strftime("%Y%m%d%H%M%S") + '.jsonl' + self.file = open(f'../output/{file_name}', 'wt', encoding='utf-8') + item['crawl_time'] = int(time.time()) + line = json.dumps(dict(item), ensure_ascii=False) + "\n" + self.file.write(line) + self.file.flush() + return item diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/run_spider.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/run_spider.py" new file mode 100644 index 0000000..ddb5567 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/run_spider.py" @@ -0,0 +1,36 @@ +#!/usr/bin/env python +# encoding: utf-8 +""" +Author: nghuyong +Mail: nghuyong@163.com +Created Time: 2019-12-07 21:27 +""" +import os +import sys +from scrapy.crawler import CrawlerProcess +from scrapy.utils.project import get_project_settings +from spiders.tweet import TweetSpider +from spiders.comment import CommentSpider +from spiders.follower import FollowerSpider +from spiders.user import UserSpider +from spiders.fan import FanSpider +from spiders.repost import RepostSpider +from spiders.search import SearchSpider + +if __name__ == '__main__': + mode = sys.argv[1] + os.environ['SCRAPY_SETTINGS_MODULE'] = 'settings' + settings = get_project_settings() + process = CrawlerProcess(settings) + mode_to_spider = { + 'comment': CommentSpider, + 'fan': FanSpider, + 'follow': FollowerSpider, + 'tweet': TweetSpider, + 'user': UserSpider, + 'repost': RepostSpider, + 'search': SearchSpider + } + process.crawl(mode_to_spider[mode]) + # the script will block here until the crawling is finished + process.start() diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/settings.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/settings.py" new file mode 100644 index 0000000..2cb257a --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/settings.py" @@ -0,0 +1,30 @@ +# -*- coding: utf-8 -*- + +BOT_NAME = 'spider' + +SPIDER_MODULES = ['spiders'] +NEWSPIDER_MODULE = 'spiders' + +ROBOTSTXT_OBEY = False + +with open('cookie.txt', 'rt', encoding='utf-8') as f: + cookie = f.read().strip() +DEFAULT_REQUEST_HEADERS = { + 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:61.0) Gecko/20100101 Firefox/61.0', + 'Cookie': cookie +} + +CONCURRENT_REQUESTS = 16 + +DOWNLOAD_DELAY = 1 + +DOWNLOADER_MIDDLEWARES = { + 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': None, + 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': None, + 'middlewares.IPProxyMiddleware': 100, + 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 101, +} + +ITEM_PIPELINES = { + 'pipelines.JsonWriterPipeline': 300, +} diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/__init__.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/__init__.py" new file mode 100644 index 0000000..ebd689a --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/__init__.py" @@ -0,0 +1,4 @@ +# This package will contain the spiders of your Scrapy project +# +# Please refer to the documentation for information on how to create and manage +# your spiders. diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/comment.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/comment.py" new file mode 100644 index 0000000..4080946 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/comment.py" @@ -0,0 +1,56 @@ +#!/usr/bin/env python +# encoding: utf-8 +""" +Author: nghuyong +Mail: nghuyong@163.com +Created Time: 2020/4/14 +""" +import json +from scrapy import Spider +from scrapy.http import Request +from spiders.common import parse_user_info, parse_time, url_to_mid + + +class CommentSpider(Spider): + """ + 微博评论数据采集 + """ + name = "comment" + + def start_requests(self): + """ + 爬虫入口 + """ + # 这里tweet_ids可替换成实际待采集的数据 + tweet_ids = ['Mb15BDYR0'] + for tweet_id in tweet_ids: + mid = url_to_mid(tweet_id) + url = f"https://weibo.com/ajax/statuses/buildComments?" \ + f"is_reload=1&id={mid}&is_show_bulletin=2&is_mix=0&count=20" + yield Request(url, callback=self.parse, meta={'source_url': url}) + + def parse(self, response, **kwargs): + """ + 网页解析 + """ + data = json.loads(response.text) + for comment_info in data['data']: + item = self.parse_comment(comment_info) + yield item + if data.get('max_id', 0) != 0: + url = response.meta['source_url'] + '&max_id=' + str(data['max_id']) + yield Request(url, callback=self.parse, meta=response.meta) + + @staticmethod + def parse_comment(data): + """ + 解析comment + """ + item = dict() + item['created_at'] = parse_time(data['created_at']) + item['_id'] = data['id'] + item['like_counts'] = data['like_counts'] + item['ip_location'] = data['source'] + item['content'] = data['text_raw'] + item['comment_user'] = parse_user_info(data['user']) + return item diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/common.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/common.py" new file mode 100644 index 0000000..9c5ab8e --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/common.py" @@ -0,0 +1,105 @@ +#!/usr/bin/env python +# encoding: utf-8 +""" +Author: rightyonghu +Created Time: 2022/10/24 +""" +import dateutil.parser + + +def base62_decode(string): + """ + base + """ + alphabet = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ" + string = str(string) + num = 0 + idx = 0 + for char in string: + power = (len(string) - (idx + 1)) + num += alphabet.index(char) * (len(alphabet) ** power) + idx += 1 + + return num + + +def reverse_cut_to_length(content, code_func, cut_num=4, fill_num=7): + """ + url to mid + """ + content = str(content) + cut_list = [content[i - cut_num if i >= cut_num else 0:i] for i in range(len(content), 0, (-1 * cut_num))] + cut_list.reverse() + result = [] + for i, item in enumerate(cut_list): + s = str(code_func(item)) + if i > 0 and len(s) < fill_num: + s = (fill_num - len(s)) * '0' + s + result.append(s) + return ''.join(result) + + +def url_to_mid(url: str): + """>>> url_to_mid('z0JH2lOMb') + 3501756485200075 + """ + result = reverse_cut_to_length(url, base62_decode) + return int(result) + + +def parse_time(s): + """ + Wed Oct 19 23:44:36 +0800 2022 => 2022-10-19 23:44:36 + """ + return dateutil.parser.parse(s).strftime('%Y-%m-%d %H:%M:%S') + + +def parse_user_info(data): + """ + 解析用户信息 + """ + # 基础信息 + user = { + "_id": str(data['id']), + "avatar_hd": data['avatar_hd'], + "nick_name": data['screen_name'], + "verified": data['verified'], + } + # 额外的信息 + keys = ['description', 'followers_count', 'friends_count', 'statuses_count', + 'gender', 'location', 'mbrank', 'mbtype', 'credit_score'] + for key in keys: + if key in data: + user[key] = data[key] + if 'created_at' in data: + user['created_at'] = parse_time(data.get('created_at')) + if user['verified']: + user['verified_type'] = data['verified_type'] + if 'verified_reason' in data: + user['verified_reason'] = data['verified_reason'] + return user + + +def parse_tweet_info(data): + """ + 解析推文数据 + """ + tweet = { + "_id": str(data['mid']), + "mblogid": data['mblogid'], + "created_at": parse_time(data['created_at']), + "geo": data['geo'], + "ip_location": data.get('region_name', None), + "reposts_count": data['reposts_count'], + "comments_count": data['comments_count'], + "attitudes_count": data['attitudes_count'], + "source": data['source'], + "content": data['text_raw'].replace('\u200b', ''), + "pic_urls": ["https://wx1.sinaimg.cn/orj960/" + pic_id for pic_id in data.get('pic_ids', [])], + "pic_num": data['pic_num'], + "user": parse_user_info(data['user']), + } + if 'page_info' in data and data['page_info'].get('object_type', '') == 'video': + tweet['video'] = data['page_info']['media_info']['mp4_720p_mp4'] + tweet['url'] = f"https://weibo.com/{tweet['user']['_id']}/{tweet['mblogid']}" + return tweet diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/fan.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/fan.py" new file mode 100644 index 0000000..5a69ba8 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/fan.py" @@ -0,0 +1,45 @@ +#!/usr/bin/env python +# encoding: utf-8 +""" +Author: nghuyong +Mail: nghuyong@163.com +Created Time: 2020/4/14 +""" +import json +from scrapy import Spider +from scrapy.http import Request +from spiders.comment import parse_user_info + + +class FanSpider(Spider): + """ + 微博粉丝数据采集 + """ + name = "fan" + base_url = 'https://weibo.com/ajax/friendships/friends' + + def start_requests(self): + """ + 爬虫入口 + """ + # 这里user_ids可替换成实际待采集的数据 + user_ids = ['7726957925'] + for user_id in user_ids: + url = self.base_url + f"?relate=fans&page=1&uid={user_id}&type=fans" + yield Request(url, callback=self.parse, meta={'user': user_id, 'page_num': 1}) + + def parse(self, response, **kwargs): + """ + 网页解析 + """ + data = json.loads(response.text) + for user in data['users']: + item = dict() + item['follower_id'] = response.meta['user'] + item['fan_info'] = parse_user_info(user) + item['_id'] = response.meta['user'] + '_' + item['fan_info']['_id'] + yield item + if data['users']: + response.meta['page_num'] += 1 + url = self.base_url + f"?relate=fans&page={response.meta['page_num']}&uid={response.meta['user']}&type=fans" + yield Request(url, callback=self.parse, meta=response.meta) diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/follower.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/follower.py" new file mode 100644 index 0000000..920c440 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/follower.py" @@ -0,0 +1,45 @@ +#!/usr/bin/env python +# encoding: utf-8 +""" +Author: nghuyong +Mail: nghuyong@163.com +Created Time: 2020/4/14 +""" +import json +from scrapy import Spider +from scrapy.http import Request +from spiders.comment import parse_user_info + + +class FollowerSpider(Spider): + """ + 微博关注数据采集 + """ + name = "follower" + base_url = 'https://weibo.com/ajax/friendships/friends' + + def start_requests(self): + """ + 爬虫入口 + """ + # 这里user_ids可替换成实际待采集的数据 + user_ids = ['7726957925'] + for user_id in user_ids: + url = self.base_url + f"?page=1&uid={user_id}" + yield Request(url, callback=self.parse, meta={'user': user_id, 'page_num': 1}) + + def parse(self, response, **kwargs): + """ + 网页解析 + """ + data = json.loads(response.text) + for user in data['users']: + item = dict() + item['fan_id'] = response.meta['user'] + item['follower_info'] = parse_user_info(user) + item['_id'] = response.meta['user'] + '_' + item['follower_info']['_id'] + yield item + if data['users']: + response.meta['page_num'] += 1 + url = self.base_url + f"?page={response.meta['page_num']}&uid={response.meta['user']}" + yield Request(url, callback=self.parse, meta=response.meta) diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/repost.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/repost.py" new file mode 100644 index 0000000..99b1ff4 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/repost.py" @@ -0,0 +1,43 @@ +#!/usr/bin/env python +# encoding: utf-8 +""" +Author: nghuyong +Mail: nghuyong@163.com +Created Time: 2020/4/14 +""" +import json +from scrapy import Spider +from scrapy.http import Request +from spiders.common import parse_tweet_info, url_to_mid + + +class RepostSpider(Spider): + """ + 微博转发数据采集 + """ + name = "repost" + + def start_requests(self): + """ + 爬虫入口 + """ + # 这里tweet_ids可替换成实际待采集的数据 + tweet_ids = ['7726957925'] + for tweet_id in tweet_ids: + mid = url_to_mid(tweet_id) + url = f"https://weibo.com/ajax/statuses/repostTimeline?id={mid}&page=1&moduleID=feed&count=10" + yield Request(url, callback=self.parse, meta={'page_num': 1, 'mid': mid}) + + def parse(self, response, **kwargs): + """ + 网页解析 + """ + data = json.loads(response.text) + for tweet in data['data']: + item = parse_tweet_info(tweet) + yield item + if data['data']: + mid, page_num = response.meta['mid'], response.meta['page_num'] + page_num += 1 + url = f"https://weibo.com/ajax/statuses/repostTimeline?id={mid}&page={page_num}&moduleID=feed&count=10" + yield Request(url, callback=self.parse, meta={'page_num': page_num, 'mid': mid}) diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/search.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/search.py" new file mode 100644 index 0000000..7683286 --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/search.py" @@ -0,0 +1,52 @@ +#!/usr/bin/env python +# encoding: utf-8 +""" +Author: rightyonghu +Created Time: 2022/10/22 +""" +import json +import re +from scrapy import Spider, Request +from spiders.common import parse_tweet_info + + +class SearchSpider(Spider): + """ + 关键词搜索采集 + """ + name = "search_spider" + base_url = "https://s.weibo.com/" + + def start_requests(self): + """ + 爬虫入口 + """ + # 这里keywords可替换成实际待采集的数据 + keywords = ['程序员晚枫'] + for keyword in keywords: + url = f"https://s.weibo.com/weibo?q={keyword}&page=1" + yield Request(url, callback=self.parse, meta={'keyword': keyword}) + + def parse(self, response, **kwargs): + """ + 网页解析 + """ + html = response.text + tweet_ids = re.findall(r'\d+/(.*?)\?refer_flag=1001030103_\'\)">复制微博地址', html) + for tweet_id in tweet_ids: + url = f"https://weibo.com/ajax/statuses/show?id={tweet_id}" + yield Request(url, callback=self.parse_tweet, meta=response.meta) + next_page = re.search('下一页', html) + if next_page: + url = "https://s.weibo.com" + next_page.group(1) + yield Request(url, callback=self.parse, meta=response.meta) + + @staticmethod + def parse_tweet(response): + """ + 解析推文 + """ + data = json.loads(response.text) + item = parse_tweet_info(data) + item['keyword'] = response.meta['keyword'] + yield item diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/tweet.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/tweet.py" new file mode 100644 index 0000000..5b6080c --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/tweet.py" @@ -0,0 +1,45 @@ +#!/usr/bin/env python +# encoding: utf-8 +""" +Author: nghuyong +Mail: nghuyong@163.com +Created Time: 2020/4/14 +""" +import json +from scrapy import Spider +from scrapy.http import Request +from spiders.common import parse_tweet_info + + +class TweetSpider(Spider): + """ + 用户推文数据采集 + """ + name = "tweet_spider" + base_url = "https://weibo.cn" + + def start_requests(self): + """ + 爬虫入口 + """ + # 这里user_ids可替换成实际待采集的数据 + user_ids = ['7726957925'] + for user_id in user_ids: + url = f"https://weibo.com/ajax/statuses/mymblog?uid={user_id}&page=1" + yield Request(url, callback=self.parse, meta={'user_id': user_id, 'page_num': 1}) + + def parse(self, response, **kwargs): + """ + 网页解析 + """ + data = json.loads(response.text) + tweets = data['data']['list'] + for tweet in tweets: + item = parse_tweet_info(tweet) + del item['user'] + yield item + if tweets: + user_id, page_num = response.meta['user_id'], response.meta['page_num'] + page_num += 1 + url = f"https://weibo.com/ajax/statuses/mymblog?uid={user_id}&page={page_num}" + yield Request(url, callback=self.parse, meta={'user_id': user_id, 'page_num': page_num}) diff --git "a/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/user.py" "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/user.py" new file mode 100644 index 0000000..f31610c --- /dev/null +++ "b/14\343\200\201\345\276\256\345\215\232\347\210\254\350\231\253/weibospider/spiders/user.py" @@ -0,0 +1,58 @@ +#!/usr/bin/env python +# encoding: utf-8 +""" +Author: nghuyong +Mail: nghuyong@163.com +Created Time: 2020/4/14 +""" +import json +from scrapy import Spider +from scrapy.http import Request +from spiders.common import parse_user_info + + +class UserSpider(Spider): + """ + 微博用户信息爬虫 + """ + name = "user_spider" + base_url = "https://weibo.cn" + + def start_requests(self): + """ + 爬虫入口 + """ + # 这里user_ids可替换成实际待采集的数据 + user_ids = ['7726957925'] + urls = [f'https://weibo.com/ajax/profile/info?uid={user_id}' for user_id in user_ids] + for url in urls: + yield Request(url, callback=self.parse) + + def parse(self, response, **kwargs): + """ + 网页解析 + """ + data = json.loads(response.text) + item = parse_user_info(data['data']['user']) + url = f"https://weibo.com/ajax/profile/detail?uid={item['_id']}" + yield Request(url, callback=self.parse_detail, meta={'item': item}) + + @staticmethod + def parse_detail(response): + """ + 解析详细数据 + """ + item = response.meta['item'] + data = json.loads(response.text)['data'] + item['birthday'] = data.get('birthday', '') + if 'created_at' not in item: + item['created_at'] = data.get('created_at', '') + item['desc_text'] = data.get('desc_text', '') + item['ip_location'] = data.get('ip_location', '') + item['sunshine_credit'] = data.get('sunshine_credit', {}).get('level', '') + item['label_desc'] = [label['name'] for label in data.get('label_desc', [])] + if 'company' in data: + item['company'] = data['company'] + if 'education' in data: + item['education'] = data['education'] + yield item diff --git "a/15\343\200\201PyQT5\345\206\231\344\272\206\344\270\252\345\217\257\350\247\206\345\214\226\345\244\251\346\260\224\346\237\245\350\257\242\350\275\257\344\273\266/Weather.py" "b/15\343\200\201PyQT5\345\206\231\344\272\206\344\270\252\345\217\257\350\247\206\345\214\226\345\244\251\346\260\224\346\237\245\350\257\242\350\275\257\344\273\266/Weather.py" new file mode 100644 index 0000000..a1b8110 --- /dev/null +++ "b/15\343\200\201PyQT5\345\206\231\344\272\206\344\270\252\345\217\257\350\247\206\345\214\226\345\244\251\346\260\224\346\237\245\350\257\242\350\275\257\344\273\266/Weather.py" @@ -0,0 +1,83 @@ +# 公众号:程序员晚枫 +# 60套Python视频教程:https://mp.weixin.qq.com/s/sO6hbVqORy7JpN-5TlaKvQ + +from PyQt5 import QtCore, QtGui, QtWidgets + +class Ui_Dialog(object): + + def setupUi(self, Dialog): + + Dialog.setObjectName("Dialog") + + Dialog.resize(600, 600) + + self.groupBox = QtWidgets.QGroupBox(Dialog) + + self.groupBox.setGeometry(QtCore.QRect(30, 20, 551, 511)) + + self.groupBox.setObjectName("groupBox") + + self.label_2 = QtWidgets.QLabel(self.groupBox) + + self.label_2.setGeometry(QtCore.QRect(20, 30, 31, 16)) + + self.label_2.setObjectName("label_2") + + self.comboBox = QtWidgets.QComboBox(self.groupBox) + + self.comboBox.setGeometry(QtCore.QRect(70, 30, 87, 22)) + + self.comboBox.setObjectName("comboBox") + + self.comboBox.addItem("") + + self.comboBox.addItem("") + + self.comboBox.addItem("") + + self.textEdit = QtWidgets.QTextEdit(self.groupBox) + + self.textEdit.setGeometry(QtCore.QRect(20, 70, 491, 411)) + + self.textEdit.setObjectName("textEdit") + + self.queryBtn = QtWidgets.QPushButton(Dialog) + + self.queryBtn.setGeometry(QtCore.QRect(490, 560, 93, 28)) + + self.queryBtn.setObjectName("queryBtn") + + self.clearBtn = QtWidgets.QPushButton(Dialog) + + self.clearBtn.setGeometry(QtCore.QRect(30, 560, 93, 28)) + + self.clearBtn.setObjectName("clearBtn") + + self.retranslateUi(Dialog) + + self.clearBtn.clicked.connect(Dialog.clearText) + + self.queryBtn.clicked.connect(Dialog.queryWeather) + + QtCore.QMetaObject.connectSlotsByName(Dialog) + + def retranslateUi(self, Dialog): + + _translate = QtCore.QCoreApplication.translate + + Dialog.setWindowTitle(_translate("Dialog", "Dialog")) + + self.groupBox.setTitle(_translate("Dialog", "城市天气预报")) + + self.label_2.setText(_translate("Dialog", "城市")) + + self.comboBox.setItemText(0, _translate("Dialog", "北京")) + + self.comboBox.setItemText(1, _translate("Dialog", "苏州")) + + self.comboBox.setItemText(2, _translate("Dialog", "上海")) + + self.queryBtn.setText(_translate("Dialog", "查询")) + + self.clearBtn.setText(_translate("Dialog", "清空")) + diff --git "a/15\343\200\201PyQT5\345\206\231\344\272\206\344\270\252\345\217\257\350\247\206\345\214\226\345\244\251\346\260\224\346\237\245\350\257\242\350\275\257\344\273\266/main.py" "b/15\343\200\201PyQT5\345\206\231\344\272\206\344\270\252\345\217\257\350\247\206\345\214\226\345\244\251\346\260\224\346\237\245\350\257\242\350\275\257\344\273\266/main.py" new file mode 100644 index 0000000..cdfc0da --- /dev/null +++ "b/15\343\200\201PyQT5\345\206\231\344\272\206\344\270\252\345\217\257\350\247\206\345\214\226\345\244\251\346\260\224\346\237\245\350\257\242\350\275\257\344\273\266/main.py" @@ -0,0 +1,84 @@ +# 公众号:程序员晚枫 +# 60套Python视频教程:https://mp.weixin.qq.com/s/sO6hbVqORy7JpN-5TlaKvQ + +import sys + +import Weather + +from PyQt5.QtWidgets import QApplication, QDialog + +import requests + +class MainDialog(QDialog): + + def __init__(self, parent=None): + + super(QDialog, self).__init__(parent) + + self.ui = Weather.Ui_Dialog() + + self.ui.setupUi(self) + + def queryWeather(self): + + cityName = self.ui.comboBox.currentText() + + cityCode = self.getCode(cityName) + + r = requests.get( + + "https://restapi.amap.com/v3/weather/weatherInfo?key=f4fd5b287b6d7d51a3c60fee24e42002&city={}".format( + + cityCode)) + + if r.status_code == 200: + + data = r.json()['lives'][0] + + weatherMsg = '城市:{}\n天气:{}\n温度:{}\n风向:{}\n风力:{}\n湿度:{}\n发布时间:{}\n'.format( + + data['city'], + + data['weather'], + + data['temperature'], + + data['winddirection'], + + data['windpower'], + + data['humidity'], + + data['reporttime'], + + ) + + else: + + weatherMsg = '天气查询失败,请稍后再试!' + + self.ui.textEdit.setText(weatherMsg) + + def getCode(self, cityName): + + cityDict = {"北京": "110000", + + "苏州": "320500", + + "上海": "310000"} + + return cityDict.get(cityName, '101010100') + + def clearText(self): + + self.ui.textEdit.clear() + +if __name__ == '__main__': + + myapp = QApplication(sys.argv) + + myDlg = MainDialog() + + myDlg.show() + + sys.exit(myapp.exec_()) \ No newline at end of file diff --git "a/16\343\200\201\347\224\250Python\345\206\231\344\272\206\344\270\252\344\272\224\345\255\220\346\243\213\346\270\270\346\210\217/PythonGomoku/.gitignore" "b/16\343\200\201\347\224\250Python\345\206\231\344\272\206\344\270\252\344\272\224\345\255\220\346\243\213\346\270\270\346\210\217/PythonGomoku/.gitignore" new file mode 100644 index 0000000..7c51ec9 --- /dev/null +++ "b/16\343\200\201\347\224\250Python\345\206\231\344\272\206\344\270\252\344\272\224\345\255\220\346\243\213\346\270\270\346\210\217/PythonGomoku/.gitignore" @@ -0,0 +1,4 @@ +__pycache__/ +.idea/ +*.exe +*.pyd diff --git "a/16\343\200\201\347\224\250Python\345\206\231\344\272\206\344\270\252\344\272\224\345\255\220\346\243\213\346\270\270\346\210\217/PythonGomoku/GomokuAi/GomokuAi.pro" "b/16\343\200\201\347\224\250Python\345\206\231\344\272\206\344\270\252\344\272\224\345\255\220\346\243\213\346\270\270\346\210\217/PythonGomoku/GomokuAi/GomokuAi.pro" new file mode 100644 index 0000000..104cdd4 --- /dev/null +++ "b/16\343\200\201\347\224\250Python\345\206\231\344\272\206\344\270\252\344\272\224\345\255\220\346\243\213\346\270\270\346\210\217/PythonGomoku/GomokuAi/GomokuAi.pro" @@ -0,0 +1,36 @@ +#------------------------------------------------- +# +# Project created by QtCreator 2019-11-06T01:16:46 +# +#------------------------------------------------- + +QT -= core gui + +TARGET = GomokuAi +TEMPLATE = lib + +DEFINES += GOMOKUAI_LIBRARY + +# The following define makes your compiler emit warnings if you use +# any feature of Qt which has been marked as deprecated (the exact warnings +# depend on your compiler). Please consult the documentation of the +# deprecated API in order to know how to port your code away from it. +DEFINES += QT_DEPRECATED_WARNINGS + +# You can also make your code fail to compile if you use deprecated APIs. +# In order to do so, uncomment the following line. +# You can also select to disable deprecated APIs only up to a certain version of Qt. +#DEFINES += QT_DISABLE_DEPRECATED_BEFORE=0x060000 # disables all the APIs deprecated before Qt 6.0.0 + +SOURCES += \ + gomokuai.cpp \ + ai.cpp \ + constants.cpp + +INCLUDEPATH += D:\ProgramPackage\Python\Python36\include + +LIBS += -LD:\ProgramPackage\Python\Python36\libs -lpython36 + +HEADERS += \ + ai.h \ + constants.h diff --git "a/16\343\200\201\347\224\250Python\345\206\231\344\272\206\344\270\252\344\272\224\345\255\220\346\243\213\346\270\270\346\210\217/PythonGomoku/GomokuAi/GomokuAi.pro.user" "b/16\343\200\201\347\224\250Python\345\206\231\344\272\206\344\270\252\344\272\224\345\255\220\346\243\213\346\270\270\346\210\217/PythonGomoku/GomokuAi/GomokuAi.pro.user" new file mode 100644 index 0000000..81cfbb3 --- /dev/null +++ "b/16\343\200\201\347\224\250Python\345\206\231\344\272\206\344\270\252\344\272\224\345\255\220\346\243\213\346\270\270\346\210\217/PythonGomoku/GomokuAi/GomokuAi.pro.user" @@ -0,0 +1,321 @@ + + + +
+ For a guide and recipes on how to configure / customize this project,
+ check out the
+ vue-cli documentation.
+
{{leixin[scope.row.type]}}
+{{leixin[scope.row.type]}}
+ +{{leixin[scope.row.type]}}
+{{leixin[scope.row.type]}}
+ +{{leixin[scope.row.type]}}
+{{leixin[scope.row.type]}}
+ ++ 新增-展开
+ + ++ 出差报销
+当前页总计:
+¥{{zj}}
+ ++ 其他报销
+当前页总计:
+¥{{qtzj}}
+ +水 滴 合 同 账 务 系 统
+{{scope.row.money_plan/xmctForm.amount*100}}%
+ +{{scope.row.money_plan/xmctForm.amount*100}}%
+ +{{leixin[scope.row.type]}}
+{{leixin[scope.row.type]}}
+ +数据添加成功!
") + + +from rest_framework.views import APIView +from rest_framework.authentication import BasicAuthentication +from rest_framework import exceptions, viewsets + + +#########################REST API 验证 +class MyAuthentication (BasicAuthentication): + def authenticate(self, request): + token = request._request.GET.get ('token') + if not token: + raise exceptions.AuthenticationFailed ('用户认证失败') + return {"alex", None} + + def authenticate_header(self, val): + pass + + +class DogView (APIView): + # authentication_classes = [MyAuthentication, ] + + def get(self, request, *args, **kwargs): + ret = {'code': 1000, 'msg': 'xxxxx'} + return HttpResponse (json.dumps (ret), status=201) + + +##########数据库查表认证 +def md5(user): + import hashlib + import time + + ctime = str (time.time ( )) + m = hashlib.md5 (bytes (user, encoding='utf-8')) + m.update (bytes (ctime, encoding='utf-8')) + return m.hexdigest ( ) + + +##---------------------登录验证 +class Login (APIView): + authentication_classes = [] # 列表里写入验证类,为空代表不需要验证 + + # permission_classes = [ApiPermission] #列表里写入权限控制类 + # parser_classes = [FileUploadParser] #单独指定解析器 + def post(self, request, *args, **kwargs): + # self.dispatch() + ret = {'data': {'email': None, 'id': None, 'mobile': None, 'rid': None, 'token': None, 'username': None, + 'name': None}, + 'meta': {'msg': "", 'status': 200}} + try: + data = request.data + user = data['username'] + pwd = data['password'] + print("用户名为:" + user + "想来登录") + # print ("用户名为:" + user + "想来登录") + obj = models.UserInfo.objects.filter (username=user, password=pwd).first ( ) + + if not obj: # 如果取不出 + ret['meta']['status'] = 1001 + ret['meta']['msg'] = "用户名密码错误" + return JsonResponse (ret) + token = md5 (user) + # 在数据表中写入或更新token + print (user + "登录成功") + models.UserToken.objects.update_or_create (user=obj, defaults={'token': token}) + ret['data']['token'] = token + ret['data']['id'] = obj.id + ret['data']['name'] = obj.name + except Exception as e: + print(e) + ret['meta']['status'] = 1001 + ret['meta']['msg'] = "请求异常" + return JsonResponse (ret) + +#通过token取个人信息 +@api_view(http_method_names=['POST']) +def getUserInfo(request): + data = request.data + token = data['token'] + try: + if not len(token)==0:#如果有token + print("token有值") + print(token+"999") + user = models.UserToken.objects.filter (token=token).first() + if user:#如果有返回用户 + user = user.user#查询数据并通过外键关键拿到用户对象 + else: + return httpback.params_error(message="别乱拿假数据过来!") + ul = UserSerializer(user,context={'request': request}) + data = ul.data + else: + return httpback.params_error(message="you have no token!") + except Exception as e: + # print(e) + return httpback.server_error( ) + + return httpback.result(data=data,message="ok") + + + +class ZhuChe(APIView): + authentication_classes = [] # 列表里写入验证类,为空代表不需要验证 + def get(self,request): + hostid = config.getHostid() + license =config.getLicense() + if license =="": + msg = "not register" + else: + if(config.init(license)): + msg = "registered" + else: + msg = "not register" + + return httpback.result(data={'hostid':hostid,'license':license},message=msg) + + def post(self,request, *args, **kwargs): + try: + data = request.data + license = data['license'] + if config.init(license): + #写入license + config.putLicense(license) + return httpback.result(message='ok') + else: + return httpback.result(code=HttpCode.paramserror,message="注册码有误") + except Exception as e: + # print(e) + return httpback.server_error ( ) +class TestData (APIView): + permission_classes = [ApiPermission2] + + def get(self, request): + ret = { + "key01": "vaule01", + "key02": "vaule02", + "key03": "vaule03", + } + return JsonResponse (ret) + + +# 获取用户主菜单 +# class GetMenus (APIView): +# def get(self, request): +# menu = { +# "data": [ +# { +# "id": 101, +# "authName": "用户管理", +# "path": "/user", +# "children": [ +# { +# "id": 102, +# "authName": "用户列表", +# "path": None, +# "children": [] +# } +# ] +# }, +# { +# "id": 201, +# "authName": "权限管理", +# "path": None, +# "children": [ +# { +# "id": 202, +# "authName": "权限管理", +# "path": None, +# "children": [] +# } +# ] +# +# } +# ], +# "meta": { +# "msg": "获取菜单列表成功", +# "status": 200 +# } +# } +# return JsonResponse (menu) + +#用户不分页 +class UserAllViewSet(viewsets.ModelViewSet): + queryset = models.UserInfo.objects.all() + serializer_class = UserSerializer + permission_classes = [IsAdminOrReadOnlyForUser, ] + # filter_backends = (DjangoFilterBackend, ) 可以全局配置,所以此处不再配置 + filter_class = UserInfo_FilterSet +class UserViewSet(viewsets.ModelViewSet): + queryset = models.UserInfo.objects.all() + pagination_class = MyPageNumberPagination + serializer_class = UserSerializer + permission_classes = [IsAdminOrReadOnlyForUser, ] + # filter_backends = (DjangoFilterBackend, ) 可以全局配置,所以此处不再配置 + filter_class = UserInfo_FilterSet + # search_fields = ('query', ) + # 核心部分就是list方法 + # def list(self, request): + # keyword = request.GET.get ('query') # 获取参数 + # print(keyword) + # if keyword is not None: # 如果参数不为空 + # # 执行filter()方法 + # queryset = models.UserInfo.objects.filter (name__contains=keyword)#在name字段找关键字 + # else: + # # 如果参数为空,执行all()方法 + # queryset = models.UserInfo.objects.all ( ) + # #serializer = UserSerializer (queryset, many=True) + # page = MyPageNumberPagination() + # page_roles =page.paginate_queryset(queryset,request) + # serializer = UserSerializer (page_roles, context={'request': request}, many=True) + # #serializer = UserSerializer (instance=page_roles, many=True) + # return page.get_paginated_response(serializer.data) # 最后返回经过序列化的数据 + + + + + +class TestViewSet(viewsets.ModelViewSet): + queryset = models.Test.objects.all() + serializer_class = TestSerializer + +class DepartmentViewSet(viewsets.ModelViewSet): + queryset = models.Department.objects.all() + serializer_class = DepartmentSerializer + permission_classes = [IsAdminOrReadOnly, ] +#单位 +class EntityViewSet(viewsets.ModelViewSet): + queryset = models.Entity_info.objects.all() + serializer_class = EntitySerializer + pagination_class = MyPageNumberPagination + +#单位不分页 +class EntityAllViewSet(viewsets.ModelViewSet): + queryset = models.Entity_info.objects.all() + serializer_class = EntitySerializer + + +# class UsertestViewSet(viewsets.ModelViewSet): +# queryset = models.UserInfo.objects.all() +# serializer_class = UserstestSerializer + +#项目 +class ProjectViewSet(viewsets.ModelViewSet): + queryset = models.Project_info.objects.all().order_by('-id')#排序一下,后建立的项目排前面 + serializer_class = ProjectSerializer + pagination_class = MyPageNumberPagination + filter_class = project_FilterSet +#项目不分页 +class ProjectAllViewSet(viewsets.ModelViewSet): + queryset = models.Project_info.objects.all().order_by('-id')#排序一下,后建立的项目排前面 + serializer_class = ProjectSerializer + filter_class = project_FilterSet + +#交通方式 +class TrafficViewSet(viewsets.ModelViewSet): + queryset = models.Traffic_type.objects.all() + serializer_class = TrafficSerializer + +#项目出差报销记帐表 +class AccountViewSet(viewsets.ModelViewSet): + queryset = models.Account_project.objects.all() + ##serializer_class = AccountSerializer + pagination_class = MyPageNumberPagination + permission_classes = [IsOwnerOrReadOnlyForAccount, ] + # serializer_class =AccountSerializer + # filter_backends = [DjangoFilterBackend] + filter_class = Account_project_FilterSet + serializers_class = Example_SERIALIZERS_DICT = { + 'list': AccountlistSerializer, + 'create': AccountSerializer, + 'update': AccountSerializer, + 'retrieve': AccountlistSerializer, + 'partial_update': AccountSerializer + } + + # def get_queryset(self): + # # queryset = self.queryset + # my = self.request.query_params.get('mylist',0) + # if my: + # user = self.request.user + # queryset = Account_project.objects.filter(expense_name = user) + # return queryset + # return models.Account_project.objects.all() + + def get_serializer_class(self): + try: + return self.serializers_class[self.action] + except KeyError: + raise # 处理不可对应的情况 + + # 群局部改(单局部改):请求数据 -[{pk:1,name=123},{pk:2,name=456},{pk:8,price:666}] + def patch(self, request, *args, **kwargs): + request_data = request.data # 数据包数据 + print(request.user) + # pk = request_data.get ('pk') + # 将单改,群改的数据都格式化成 pks=[要需要的对象主键标识] | request_data=[每个要修改的对象对应的修改数据] + # if pk and isinstance (request_data, dict): # 单改 + # pks = [pk, ] + # request_data = [request_data, ] + if isinstance (request_data, list): # 群改 + pks = [] + # 遍历前台数据[{pk:1, name:123}, {pk:3, price:7}, {pk:7, publish:2}],拿一个个字典 + for dic in request_data: + pk = dic.pop ('pk', None) # 返回pk值 + if pk: + pks.append (pk) + # pk没有传值 + else: + return Response ({ + 'status': 1, + 'msg': '参数错误' + }) + else: + return Response ({ + 'status': 1, + 'msg': '参数错误' + }) + # pks与request_data数据筛选, + # 1)将pks中的没有对应数据的pk与数据已删除的pk移除,request_data对应索引位上的数据也移除 + # 2)将合理的pks转换为 objs + objs = [] + new_request_data = [] + for index, pk in enumerate (pks): + try: + # 将pk合理的对象数据保存下来 + book_obj = models.Account_project.objects.get (id=pk) + objs.append (book_obj) + # 对应索引的数据也保存下来,并且加人审批人和审批时间 + spobj = request_data[index] + # spobj.approve_id = request.user + # spobj.approvetime = datetime.datetime.now() + spobj.update(approve_id=request.user.id) + spobj.update(approvetime=datetime.datetime.now()) + new_request_data.append (spobj) + # spobj = {'approve_id': user} + # spobj.update(approve_id = user) + # print(spobj) + except Exception as ex : + print(ex) + # 重点:反面教程 - pk对应的数据有误,将对应索引的data中request_data中移除 + # 在for循环中不要使用删除 + # index = pks.index(pk) + # request_data.pop(index) + continue + # 生成一个serializer对象 + try: + book_ser = serializers.AccountlistSerializer (instance=objs, data=new_request_data, partial=True, many=True) + book_ser.is_valid (raise_exception=True) + book_objs = book_ser.save ( ) + return Response ({ + 'status': 200, + 'msg': 'ok', + 'results': serializers.AccountlistSerializer (book_objs, many=True).data + }) + except Exception as ex : + print(ex) + return Response ({ + 'status': 501, + 'msg': 'err', + 'results': serializers.AccountlistSerializer (book_objs, many=True).data + }) + # new_params = list() + # # 直接获取 body(请求体, 二进制数据), 解码后, 进行切割 + # for param in request.body.decode(encoding="utf-8").split("&"): + # if "approve_id" in param: + # # 修改参数值, 并重新拼接参数 + # new_str = "approve_id=" + param.split("=")[1].replace("-", " ") + # new_params.append(new_str) + # else: + # new_params.append(param) + # # 重新构造请求体, 进行编码后, 重新赋值给 request._body + # # 注意: 是 request._body, 因为 request.body 是不可修改的, 但是 body 属性继承自 _body 属性, 所以直接修改 _body 属性 + # request._body = "&".join(new_params).encode(encoding="utf-8") + # + # ... + # + # def params_replace(self, data): + # # 按需求, 对请求参数中的值做出修改 + # name = data.patch("approve_id") + # if name: + # data["pprove_id"] = name.replace("-", " ") + # return data + # else: + # return None + + +#非项目出差报销 +class Account_normalViewSet(viewsets.ModelViewSet): + queryset = models.Account_normal.objects.all() + #serializer_class = Account_normalSerializer + pagination_class = MyPageNumberPagination + permission_classes = [IsOwnerOrReadOnlyForAccount, ] + filter_class = Account_normal_FilterSet + serializers_class = Example_SERIALIZERS_DICT = { + 'list': normallistSerializer, + 'create': Account_normalSerializer, + 'update': Account_normalSerializer, + 'retrieve': normallistSerializer, + 'partial_update': Account_normalSerializer + } + def get_serializer_class(self): + try: + return self.serializers_class[self.action] + except KeyError: + raise # 处理不可对应的情况 + def patch(self, request, *args, **kwargs): + request_data = request.data # 数据包数据 + # pk = request_data.get ('pk') + # 将单改,群改的数据都格式化成 pks=[要需要的对象主键标识] | request_data=[每个要修改的对象对应的修改数据] + # if pk and isinstance (request_data, dict): # 单改 + # pks = [pk, ] + # request_data = [request_data, ] + if isinstance (request_data, list): # 群改 + pks = [] + # 遍历前台数据[{pk:1, name:123}, {pk:3, price:7}, {pk:7, publish:2}],拿一个个字典 + for dic in request_data: + pk = dic.pop ('pk', None) # 返回pk值 + if pk: + pks.append (pk) + # pk没有传值 + else: + return Response ({ + 'status': 1, + 'msg': '参数错误' + }) + else: + return Response ({ + 'status': 1, + 'msg': '参数错误' + }) + # pks与request_data数据筛选, + # 1)将pks中的没有对应数据的pk与数据已删除的pk移除,request_data对应索引位上的数据也移除 + # 2)将合理的pks转换为 objs + + + objs = [] + new_request_data = [] + for index, pk in enumerate (pks): + try: + # 将pk合理的对象数据保存下来 + book_obj = models.Account_normal.objects.get (id=pk) + objs.append (book_obj) + # 对应索引的数据也保存下来,并且加人审批人和审批时间 + spobj = request_data[index] + spobj.update(approve_id=request.user.id) + spobj.update(approvetime=datetime.datetime.now()) + new_request_data.append (spobj) + except: + # 重点:反面教程 - pk对应的数据有误,将对应索引的data中request_data中移除 + # 在for循环中不要使用删除 + # index = pks.index(pk) + # request_data.pop(index) + continue + # 生成一个serializer对象 + try: + book_ser = serializers.normallistSerializer (instance=objs, data=new_request_data, partial=True, many=True) + book_ser.is_valid (raise_exception=True) + book_objs = book_ser.save ( ) + return Response ({ + 'status': 200, + 'msg': 'ok', + 'results': serializers.normallistSerializer (book_objs, many=True).data + }) + except Exception as ex : + return Response ({ + 'status': 501, + 'msg': 'err', + 'results': serializers.normallistSerializer (book_objs, many=True).data + }) + + + + +#查询视图 +class Account_viewViewSet(viewsets.ModelViewSet): + queryset = models.Account_view.objects.all() + serializer_class = Account_viewSerializer + pagination_class = MyPageNumberPagination + filter_class = Account_view_FilterSet + permission_classes = [IsOwnerOrReadOnlyForAccountView, ] + + + +#附件 +class attachmentViewSet(viewsets.ModelViewSet): + queryset = models.attachment.objects.all() + serializer_class = attachmentSerializer + permission_classes = [IsAdminOrReadOnly, ] + # pagination_class = MyPageNumberPagination + #删除的同时把存储的文件也删除了 + def perform_destroy(self, instance): + instance.file.delete (save=False) + instance.delete ( ) + +#合同信息 +class Contract_infoViewSet(viewsets.ModelViewSet): + queryset = models.Contract_info.objects.all() + serializer_class = Contract_infoSerializer + permission_classes = [IsAdminOrReadOnly, ] + pagination_class = MyPageNumberPagination + filter_class = Contract_info_FilterSet + +#合同财务计划 +class Contract_planViewSet(viewsets.ModelViewSet): + queryset = models.Contract_plan.objects.all() + serializer_class = Contract_planSerializer + permission_classes = [IsAdminOrReadOnly, ] + filter_class = Cotract_plan_FilerSet + # pagination_class = MyPageNumberPagination diff --git a/flask/apps/app1/urls.py "b/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/db.sqlite3" similarity index 100% rename from flask/apps/app1/urls.py rename to "1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/db.sqlite3" diff --git "a/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/manage.py" "b/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/manage.py" new file mode 100644 index 0000000..294ae9c --- /dev/null +++ "b/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/manage.py" @@ -0,0 +1,21 @@ +#!/usr/bin/env python +"""Django's command-line utility for administrative tasks.""" +import os +import sys + + +def main(): + os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'ApiServer.settings') + try: + from django.core.management import execute_from_command_line + except ImportError as exc: + raise ImportError( + "Couldn't import Django. Are you sure it's installed and " + "available on your PYTHONPATH environment variable? Did you " + "forget to activate a virtual environment?" + ) from exc + execute_from_command_line(sys.argv) + + +if __name__ == '__main__': + main() diff --git "a/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/media/files/\345\220\210\345\220\214\351\231\204\344\273\266/1/2.jpg" "b/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/media/files/\345\220\210\345\220\214\351\231\204\344\273\266/1/2.jpg" new file mode 100644 index 0000000..80ca190 Binary files /dev/null and "b/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/media/files/\345\220\210\345\220\214\351\231\204\344\273\266/1/2.jpg" differ diff --git "a/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/media/files/\345\233\276\347\211\2071.jpg" "b/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/media/files/\345\233\276\347\211\2071.jpg" new file mode 100644 index 0000000..9392162 Binary files /dev/null and "b/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/media/files/\345\233\276\347\211\2071.jpg" differ diff --git "a/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/\344\275\277\347\224\250\350\257\264\346\230\216.md" "b/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/\344\275\277\347\224\250\350\257\264\346\230\216.md" new file mode 100644 index 0000000..db0b1ec --- /dev/null +++ "b/1\343\200\201\345\220\210\345\220\214\347\263\273\347\273\237/contract-accounting-system-master/\346\234\215\345\212\241\345\231\250\345\220\216\347\253\257/\344\275\277\347\224\250\350\257\264\346\230\216.md" @@ -0,0 +1,309 @@ +2022最强Python学习资料大礼包:https://mp.weixin.qq.com/s/sO6hbVqORy7JpN-5TlaKvQ + +==================================== + +# docker一键安装 + +``` +docker run -itd --name dbserver --restart=always -p 3306:3306 registry.cn-shanghai.aliyuncs.com/liu008/dbserver:1.1 + +docker run --link=dbserver:db --env DBIP=db --env DBPORT=3306 -p 8080:8080 -p 8022:22 -itd --name app --restart=always registry.cn-shanghai.aliyuncs.com/liu008/hetong:2.1 + +``` +**记得对外开放8080端口** + +# 一、软件系统构成: + +## 1.1 功能介绍 + +本系统是一个针对于中小企业的**合同管理**与**员工出差费用报销管理**。其中以项目为主线,针对项目进行出货合同(收款),和进货合同(付款)的记录管理。合同其中还包含资金和发票的计划管理,让管理人员一目标了然。另外,报销管理模块也可以与项目进行挂钩,方便管理人员核算出整体项目的成本与利润。总之这是一个不求功能复杂,界面简洁的公司合同帐务管理软件。 + +## 1.2 架构 + +系统采用BS架构,前后端分离构建,前端WEB服务器(VUECLI架构),后端采用DJANGO;数据库采用MYSQL + +## 1.3 WEB服务器环境: + +nodeJS --version v14.13.1 + +npm -version 6.14.8 + +## 1.4 API服务器环境: + +PYTHON:3.7 + +``` +# pip list +Package Version +------------------- ------- +asgiref 3.2.10 +Cython 0.29.21 +Django 3.1.2 +django-filter 2.4.0 +djangorestframework 3.12.1 +pip 20.2.3 +PyMySQL 0.10.1 +pytz 2020.1 +setuptools 50.3.0 +sqlparse 0.4.1 +wheel 0.35.1 +``` + +## 1.5 数据库环境: + +数据库安装MYSQL 版本 > 5.7 + +默认以下配置为和API服务器安装在同一台机器,可以自行改动,只需求在API服务中更改配置文件 + +数据库名:zw + +用户名:zw + +用户密码:zw123 + +``` +ApiServer/settings.py 文件中 +DATABASES = { + 'default': { + # 'ENGINE': 'django.db.backends.sqlite3', + # 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), + 'ENGINE': 'django.db.backends.mysql', + 'NAME': 'zw', + 'USER': 'zw', + 'PASSWORD': 'zw123', + 'HOST': '127.0.0.1', + 'PORT':'3306', + } +} +``` + +## 1.6 访问过程 + +用户浏览器--------->WEB服务器------>API服务器---------->MYSQL数据库 + + + +# 二、系统注册: + +1.安装部署成功后,用户通过浏览器(不支持IE)输入http://web服务器IP:8080 自动跳转到注册页面。将hostid复制下来,用来获取license注册 + +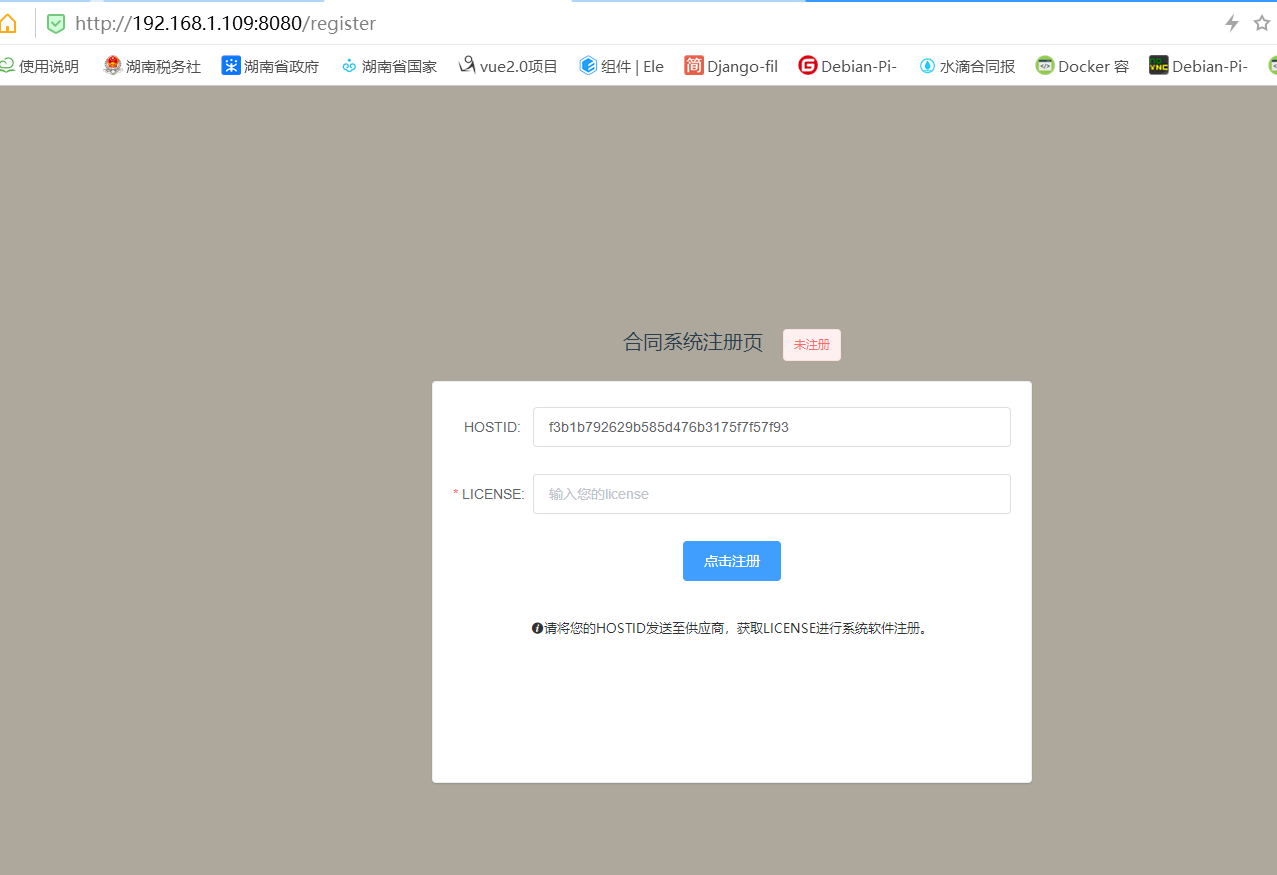 + +2.注册成功后,自动跳转至登录页面。 + + + +# 三、用户登录 + +1. **初始管理员 登录用户名:admin 密码:123456** + + + +**2.登录成功后进入主页面** + + + + + +# 四、信息管理 + +## 4.1 用户信息 + + + + 用户信息即本系统使用人员(公司员工)的帐号管理,用户默认包含首次登录的admin帐户,默认密码:123456 登录后建议立即更改密码。 + +**帐号:** + + 建议使用手机号作为帐号。 + +**部门:** + + 公司内部的部门信息,方便对不同用户进行分类。需要预先在部门信息里进行新建部门。 + +**角色:** + + 角色即权限,分为管理员和普通用户 + + 普通用户:不能增加、修改、删除用户,在只在页面右上角个人中心修改自己的密码。 + + 管理员:可以做一切操作。同时管理员也是可以更改自己或其它用户为普通用户,**所以必须保证系统内至少有一个管理员帐号**。 + +**状态:** + + 当状态为非激活状态时该用户将不能再进行登录。 + +**删除:** + + 只有管理员才可以操作,但是如果该用户存在其它关联数据:比如报销内容,在这种情况下是不允许删除的(会有报错提示,阻止该行为)。因为一旦删除会造成帐务混乱对不上人员。人员离职正确的做法应该是在点击状态条目使之处理非激活状态即可。 + +## 4.2 部门信息 + +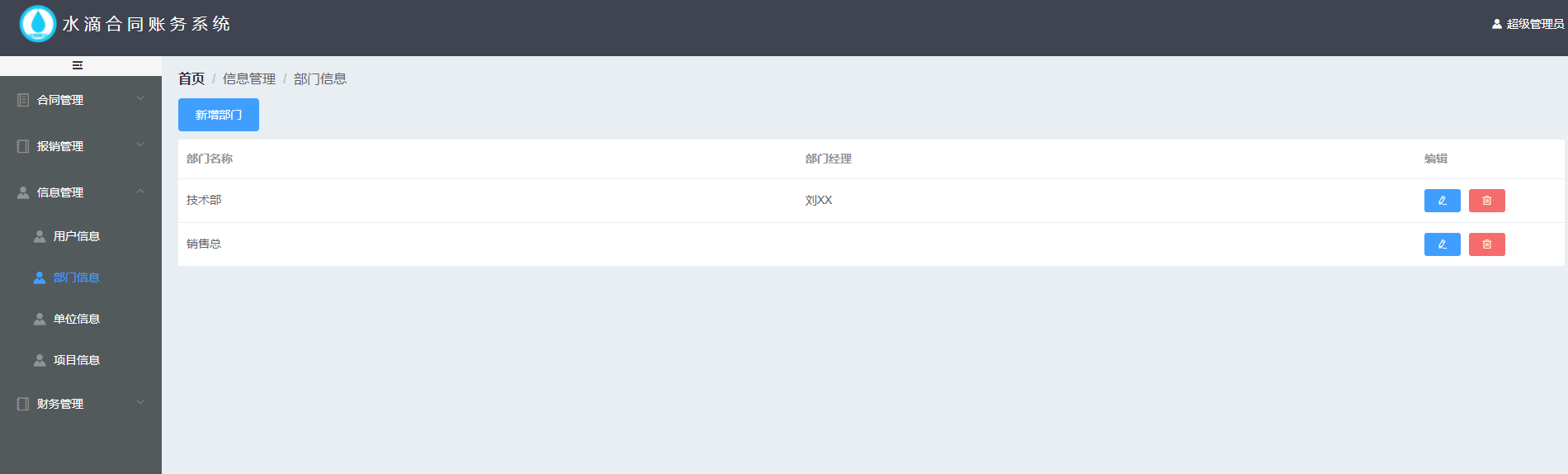 + +## 4.3 单位信息 + +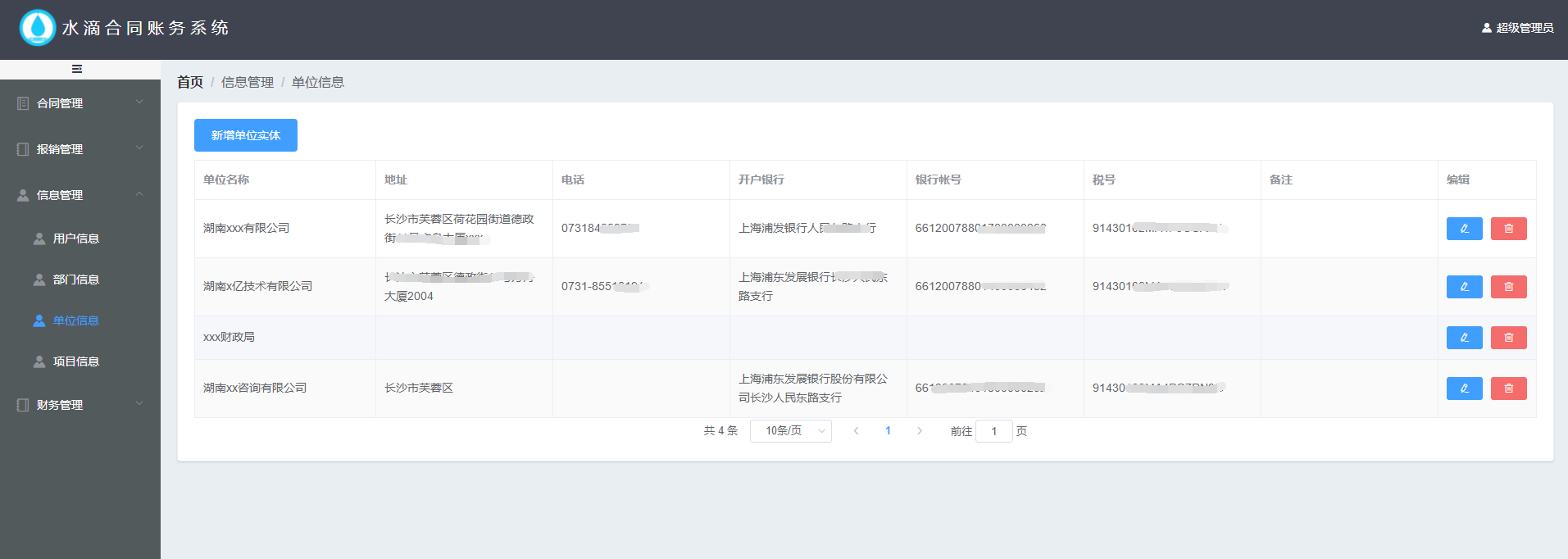 + + 单位实体用于记录合同系统中所涉及的单位或公司信息,只有单位名称是必写项(因此如果合同涉及是个人的话可以写对对方姓名)。 + +## 4.4 项目信息 + +项目信息就是针对某个工程项目先新立项目名称,后期可以与合同、报销相关联。 + +**客户对象:**指些项目的客户是哪个单位实体 + +**主体公司:**是指该项目是哪个公司的盈利项项目(这里主要考虑使用本系统的公司,名下可能会注册有多家公司的情况)。一般就是指使用本全合同系统的公司。 + +# 五、合同管理 + +## 5.1 项目合同 + +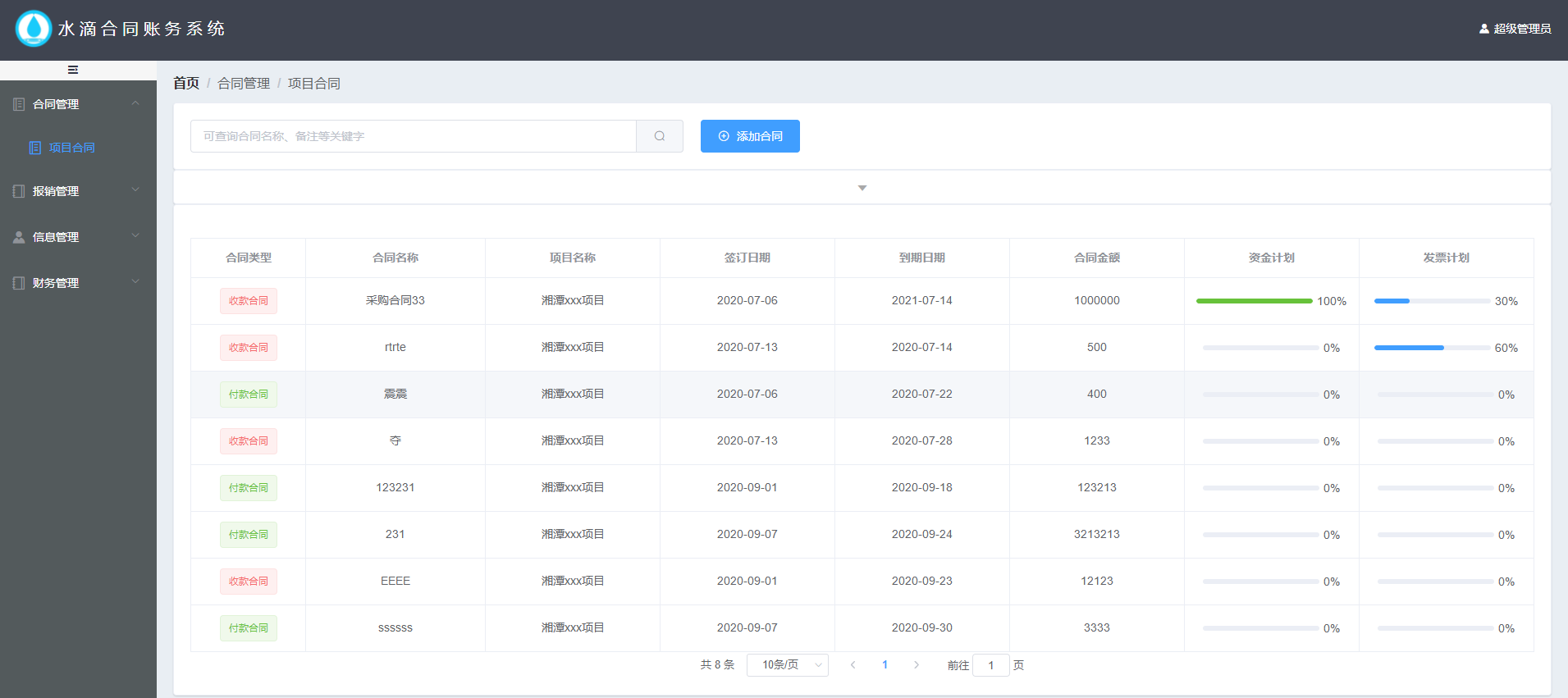 + +### 5.1.1 添加合同 + +点击此页面中点击添加合同即可新增。 + +- **合同类型** + + 类型分为:收款、付款 收款合同是指卖东西出去,付款合同是指针对项目买入的成本。 + +- **项目名称** + + 点击下拉可选择此合同对应的项目。 + +- **合同名称** + + 可以自行定义合同的名称 + +- **合同金额** + + 合同上涉及的总金额 + +- **合同本方** + + 指是谁在收款/付款 + +- **合同对方** + + 指是在向谁收款/付款 + +- 签订日期 + +- 到期日期 + + 合同的整体截至日期,一般指合同的最后履约时间。 + +- 税金成本 + + 此项不是必选项,如有必要可以记录此合同执行后,我方要缴纳多少税款。 + +- 备注 + + 此项不是必选项 + + + +## 5.2 修改合同 + +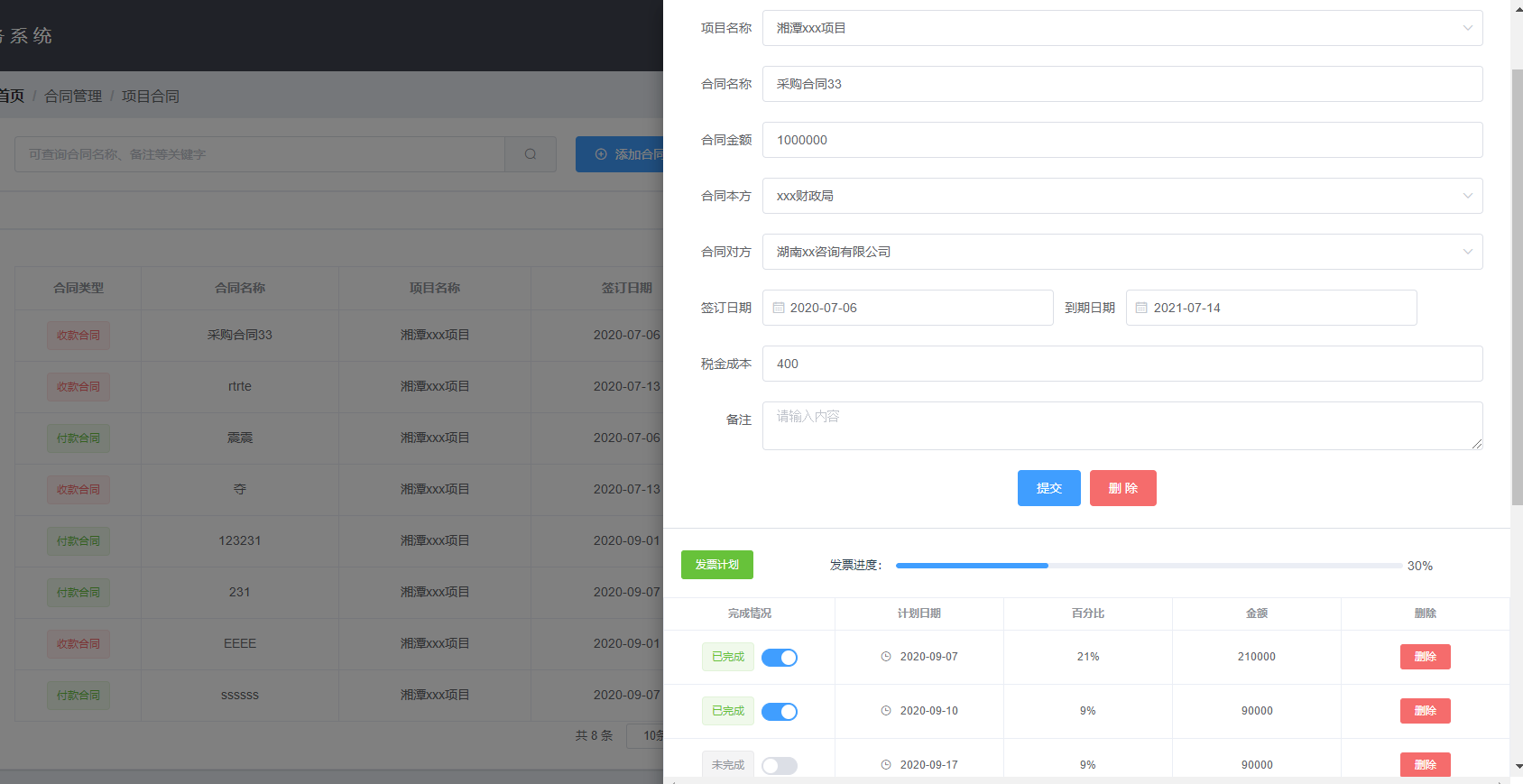 + +在合同列表中点击即可展开合同的详细信息,在详细信息中可以修改、删除合同。同进在修改合同的弹出页中可以进行:发票计划、资金计划、合同附件的操作。 + +### 5.2.1 发票计划 + +**介绍:**发票计划是指合同涉及的发票何时开具并收到。合同金额所涉及的发票是一次性全部开具出去或收票,还是分阶段。做了计划之后,点击完成状态开关按键即可设置此计划是否已完成。所有已经完成的计划,都会被显示到计划进度条中。 + +- **新增发票计划:** + + 点击发票计划按键即可新增发票计划。可以直接写入总金额的百分比和日期,先点击生成计划。生成计划之后才能点击提交。也可以在生成时不按照总金额的百分比,而是具体金额生成,只需要点击切换即可。 + +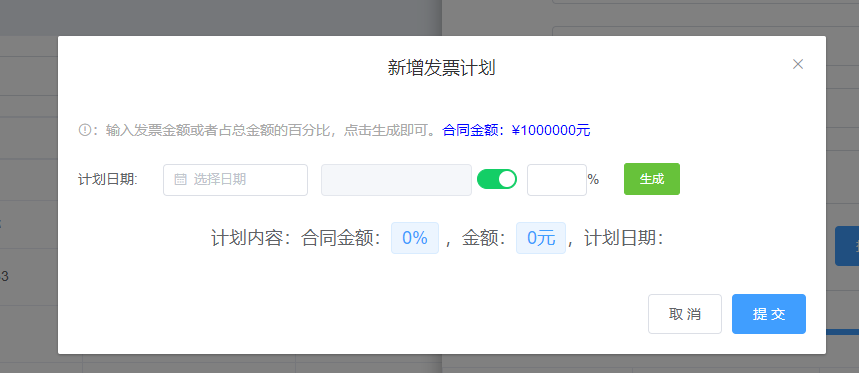 + +- **完成情况** + + 提交计划后,默认是处于未完成状态。未完成的计划是不会显示到进度条中去的。点击旁边的切换开关即可使之变成完成情况。还可以从完成切换回未完成。 + +- **删除** + +- **发票进度** + + 所有已经完成的计划会合并显示到发票进度。 + +### 5.2.2 资金计划 + + 操作和显示与发票计划一样。但是其代表的是真实的资金收付款情况。已经到账的应被视为已经完成,如果是项目尾款还未收到或付出,则应该被设置为未完成。 + +### 5.2.3 合同附件 + + 用户可以上传该合同相关的文件到服务器,后期方便下载查阅。 + + + +## 5.3 合同查询 + + + + 可以针对合同名称、项目名称、备注 进行关键字查询合同条目。也可以点击展开隐藏查询框进行,基于行合同签订时处于的年份、下拉选择具体项目(一个项目一般有进货出货多个关联合同)、合同类型(收、付款)进行查询。 + + + +# **六、报销管理** + + 报销管理里能操作和显示的都是基于当前操作者(**本人**)的报销。报销管理包含“**新增报销**”和“**报销查询**”两个部分,其中 新增报销中显示的是该用户最近新建的但是尚未经过管理人员(经理、或财务)审批的报销条目。而报销查询可以基于各种条件进行综合查询,但是只局限于查询自己本人的报销记录。 + + 另外,报销被分为两大类型:项目报销、其他报销。 + +## 6.1 新增报销 + + 点击“**新增展开**”后,可以填写用户需求报销的内容。其中分为**“出差报销”**和**“其它报销”**,两个类型。 + +- **出差报销** + + 是指人员去到外地出差的报销,会涉及交通费和住宿、出差补贴之类的,一般都是和项目挂钩,方便后期计入项目成本。如果没有明确项目或是项目还未成形,可以先在信息管理里自定义一个项目名称,再与之挂钩。标星号的都是必选项。**注**:补贴金额默认为50元一天。与你公司实际情况不符合,可以要求做代码更改。 + +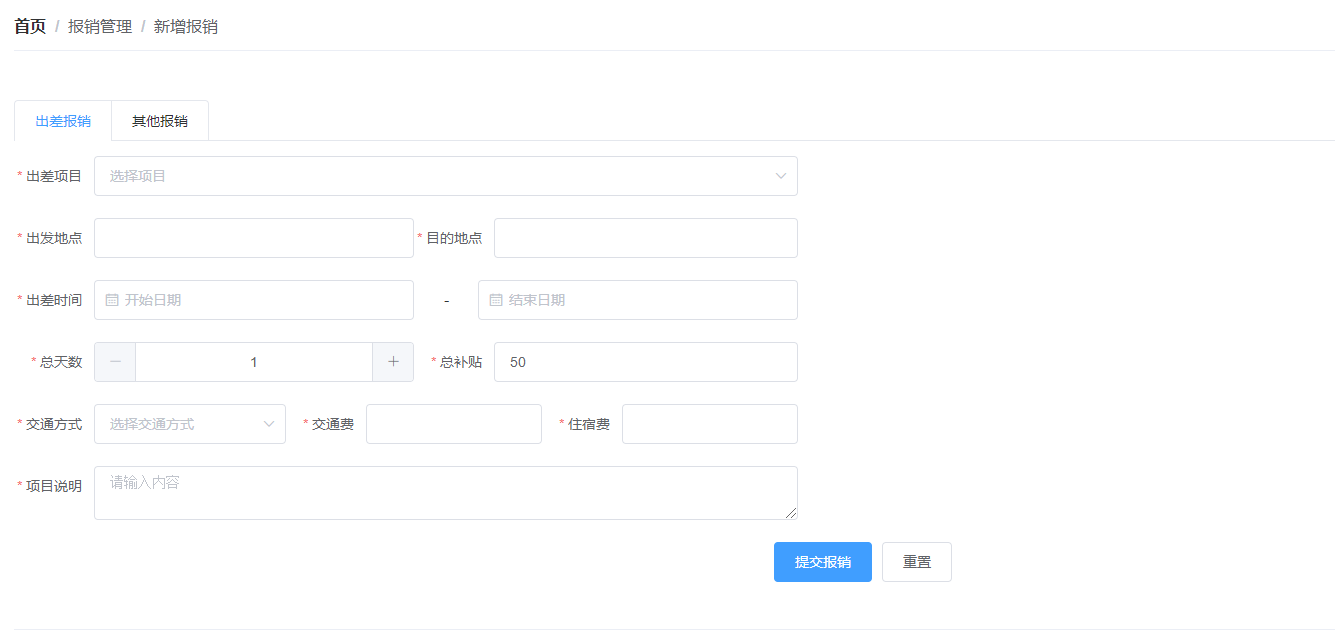 + + + +- **其他报销** + + 其他报销是指不记录出差行程的报销,比如:请吃饭,或是采购了办公用品之类。可以作为出差报销的补充,也可以是单独的报销。它不需要强制与项目进行挂钩。 + +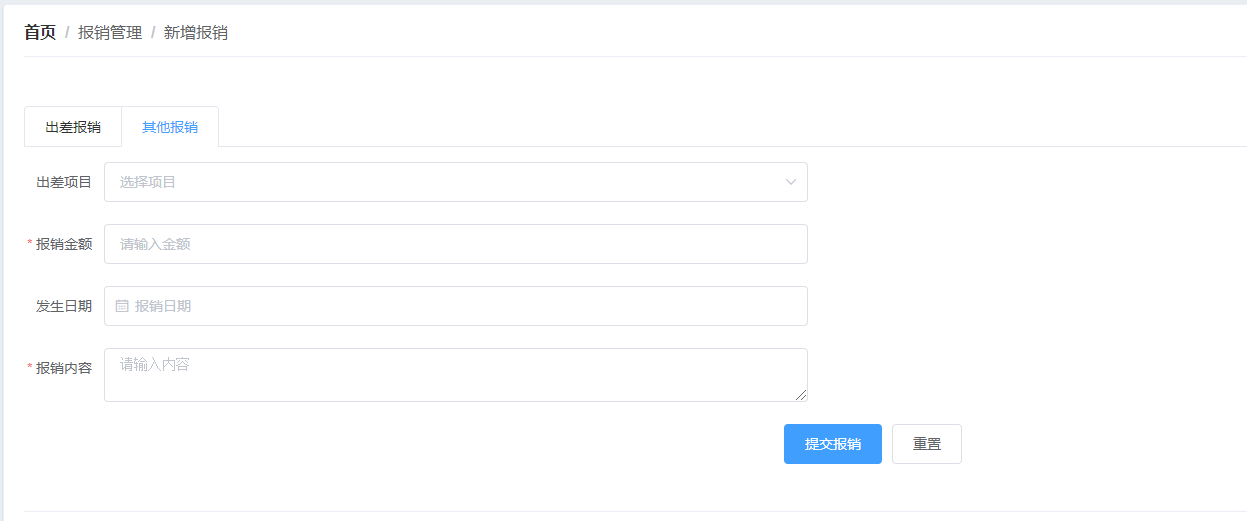 + +- **查看和修改、删除报销** + + 在新增报销页下显示了本人当前已经填写但还未审计通过的报销条目,如果需要修改或删除可以直接点击后面的编辑项目。 + + 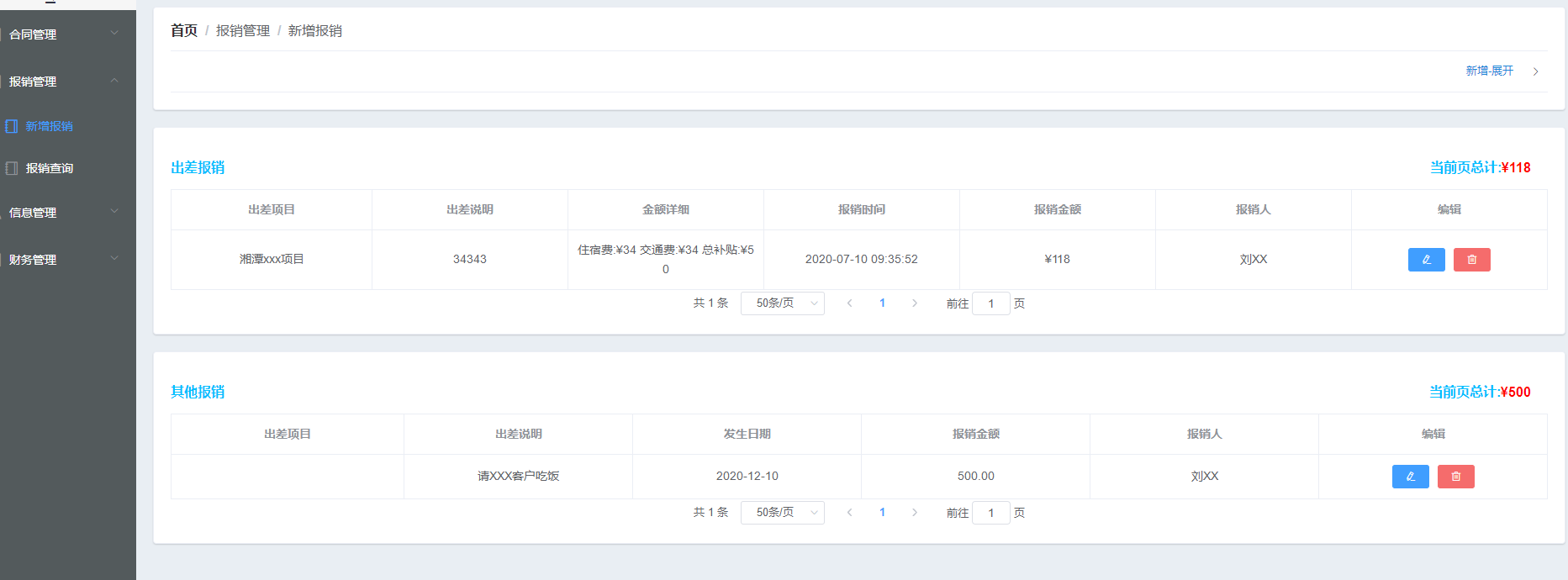 + + + +## 6.2 报销查询 + + 此页面可以根据不同条件查询用户本人所有的报销记录。 + +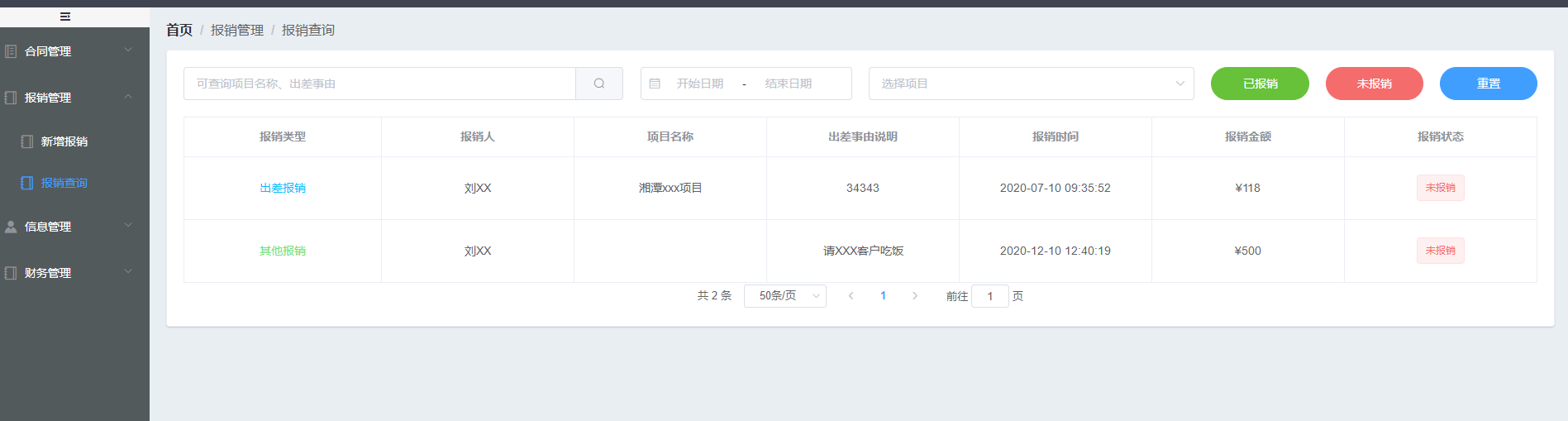 + + + +# 七、财务管理 + + 该模块是给管理和查询所有的人报销情况,分为**“报销审批”**和**“综合查询”**两个内容。其中报销审批用于管理人员对各个员工报销进行审批;综合查询是统一查询所有人的报销内容。 + +## 7.1 报销审批 + + 此页包含两个列表,其中上面的列表显示最近提交过来的所有报销,可以根据条件进行过滤显示。钩选相应的报销条目后再点击“报销”按钮可以批量审批报销。报销后条目状态将变为已报销状态。只限于管理员才可以进行此操作。 + + 另外,下面的列表显示的所有已经报销的内容。如果发现操作有误,管理员可以对相应条目钩选后点击撤销。撤销之后,状态将变回未报销。 + +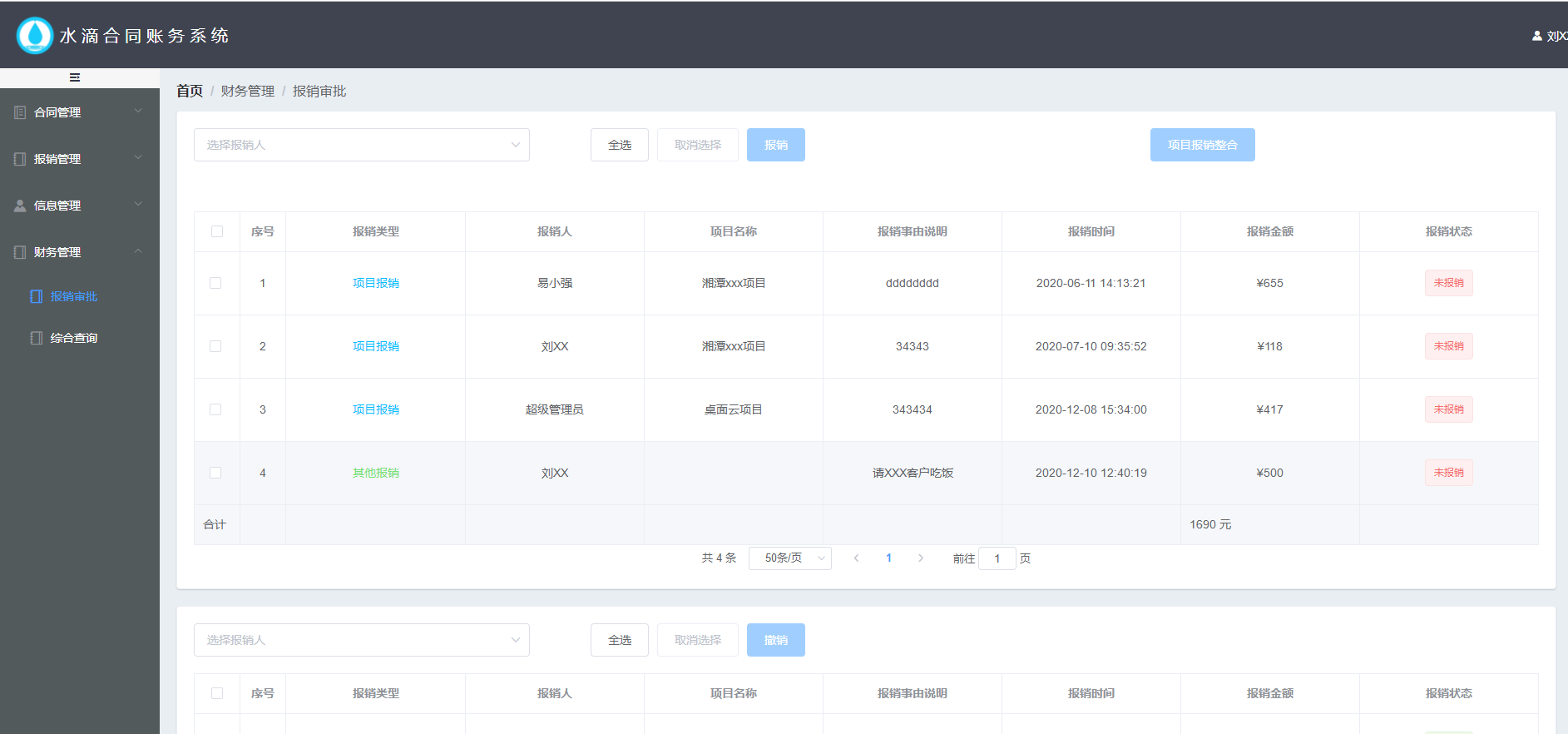 + +## 7.2 综合查询 + + 综合查询只作查询之用,不能修改或审批。可以按条件过滤查询所有人用的报销。或种条件可以叠加组合进行查询。如果取消条件可以在在各个条件中删除或重置。其中重置按键和已报销、未报销为一组,是指删除已报销、未报销的条件约束。如果查看全部最快速的办法是重新点击左则“综合查询”进行页面刷新。 + +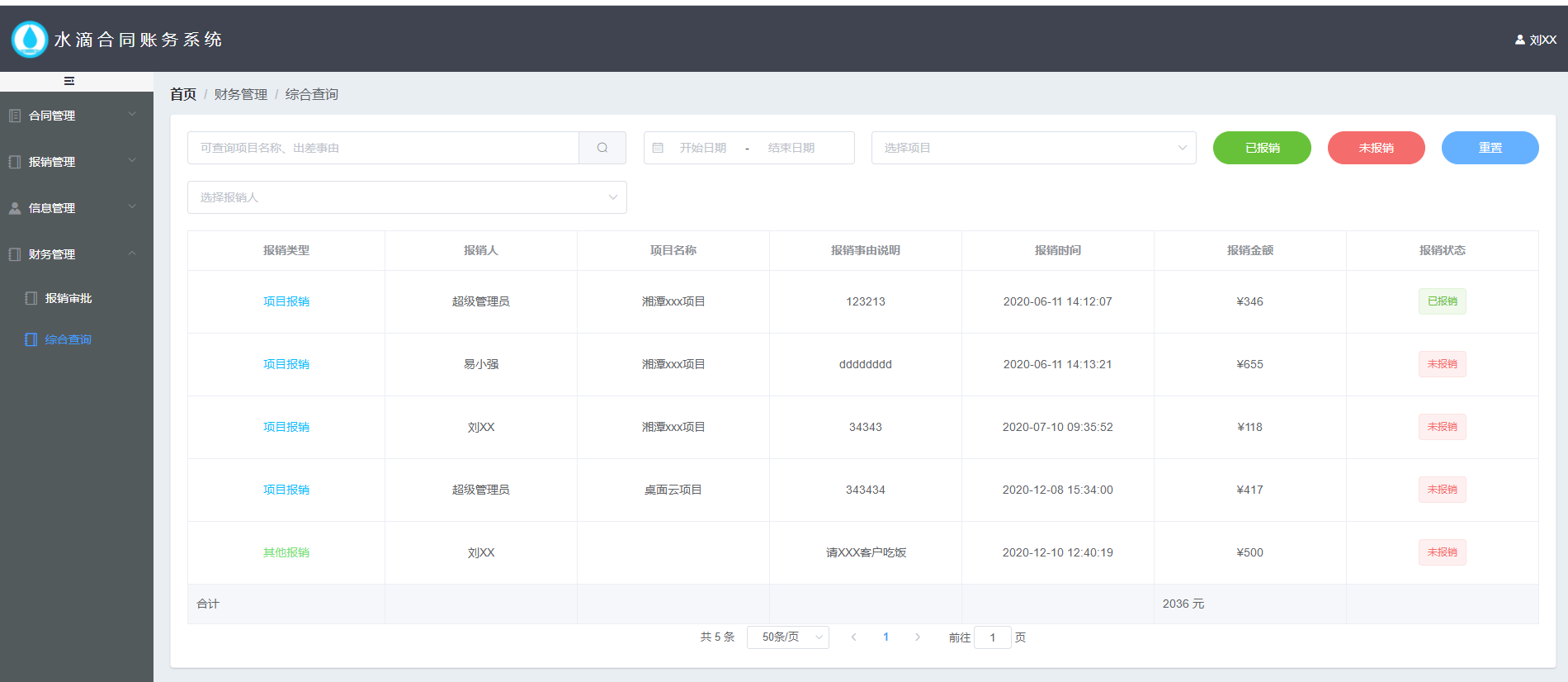 + diff --git "a/20\343\200\201\350\241\250\347\231\275\347\275\221\347\253\231/index.css" "b/20\343\200\201\350\241\250\347\231\275\347\275\221\347\253\231/index.css" new file mode 100644 index 0000000..ba66476 --- /dev/null +++ "b/20\343\200\201\350\241\250\347\231\275\347\275\221\347\253\231/index.css" @@ -0,0 +1,290 @@ +* { + box-sizing: border-box; +} + +body { + align-items: center; + background-color: #f9bf3b; + display: flex; + justify-content: center; + min-height: 100vh; +} + +:root { + --height: 300; + --width: 200; + --depth: 150; + --drawerSize: calc((var(--height) / 3) - 10); + --drawerHole: calc((var(--height) - ((10 * 4) + (10 + 30))) / 3); +} + +.chest { + height: calc(var(--height) * 1px); + transform: rotateX(-30deg) rotateY(40deg); + transform-style: preserve-3d; + width: calc(var(--width) * 1px); +} + +.chest__panel { + height: 100%; + position: absolute; + transform-style: preserve-3d; + width: 100%; +} + +.chest__panel:after { + content: ''; + display: block; + height: 100%; + width: 100%; +} + +.chest__panel--front { + transform: translate3d(0, 0, calc(var(--depth) / 2 * 1px)); +} + +.chest__panel--front:after { + background: #5b5b5b; + content: ''; + height: 4px; + position: absolute; + top: -2px; + width: 100%; +} + +.chest__panel--front-frame { + border: 10px solid #5b5b5b; + border-bottom-width: 30px; + border-top-width: 10px; + transform: translate3d(0, 0, 0); +} + +.chest__panel--front-frame:before { + background: #5b5b5b; + content: ''; + height: 20px; + left: 0; + position: absolute; + top: calc(var(--drawerHole) * 1px); + width: 100%; +} + +.chest__panel--front-frame:after { + background: #5b5b5b; + content: ''; + height: 20px; + left: 0; + position: absolute; + top: calc(var(--drawerHole) * 2px + 20px); + width: 100%; +} + +.chest__panel--back { + background: #5b5b5b; + transform: translate3d(0, 0, calc(var(--depth) / 2 * -1px)); +} + +.chest__panel--back:after { + background: #000; + transform: translate3d(0, 0, 1px); +} + +.chest__panel--top { + background: #474747; + bottom: 100%; + height: calc(var(--depth) * 1px); + left: 0; + transform: rotateX(90deg) translate3d(0, 50%, 1px); + transform-origin: bottom; + transform-style: preserve-3d; +} + +.chest__panel--top:after { + background: #1a1a1a; + transform: translate3d(0, 0, -1px); +} + +.chest__panel--bottom { + background: #474747; + height: calc(var(--depth) * 1px); + left: 0; + top: 100%; + transform: translateY(-50%) rotateX(90deg); +} + +.chest__panel--bottom:after { + background: #0d0d0d; + transform: translate3d(0, 0, 1px); +} + +.chest__panel--right { + background: #323232; + right: 0; + transform: translate3d(0, 0, calc(var(--depth) / 2 * 1px)) rotateY(-90deg); + transform-origin: right center; + width: calc(var(--depth) * 1px); +} + +.chest__panel--right:after { + background: #1a1a1a; + transform: translate3d(0, 0, 1px); +} + +.chest__panel--left { + width: calc(var(--depth) * 1px); + left: 0; + background: #323232; + transform-origin: left center; + transform: translate3d(0, -1px, calc(var(--depth) / 2 * 1px)) rotateY(90deg); +} + +.chest__panel--left:after { + background: #1a1a1a; + transform: translate3d(0, 0, 1px); +} + +.chest-drawer { + height: calc(var(--drawerSize) * 1px); + left: 0; + position: absolute; + top: 0; + transition: transform 0.25s; + transform-style: preserve-3d; + width: 100%; +} + +.chest-drawer--top, +.chest-drawer--middle, +.chest-drawer--bottom { + transform: translate3d(0, 0, calc(var(--depth) * 0.51px)); +} + +.chest-drawer--top { + top: 5px; + z-index: 3; +} + +.chest-drawer--middle { + top: calc((var(--drawerSize) + 10) * 1px); + z-index: 2; +} + +.chest-drawer--bottom { + top: calc((var(--drawerSize) * 2 + 15) * 1px); + z-index: 1; +} + +.chest-drawer details, +.chest-drawer summary { + background: #303030; + cursor: pointer; + height: 100%; + left: 0; + list-style: none; + position: absolute; + outline: 0; + top: 0; + transition: transform 0.25s; + transform: translate3d(0, 0, 0); + width: 100%; +} + +.chest-drawer details:after, +.chest-drawer summary:after { + background: #adadad; + content: ''; + height: 5%; + left: 50%; + position: absolute; + top: 10%; + transform: translate(-50%, 0); + width: 40%; +} + +.chest-drawer details::-webkit-details-marker, +.chest-drawer summary::-webkit-details-marker { + display: none; +} + +.chest-drawer details:hover:not([open]) { + transform: translate3d(0, 0, calc(var(--depth) * 0.05px)); +} + +.chest-drawer details[open], +.chest-drawer details[open] ~ .chest-drawer__structure { + transform: translate3d(0, 0, calc(var(--depth) * 0.9px)); +} + +.chest-drawer__panel { + height: 100%; + position: absolute; + transform-style: preserve-3d; + width: 100%; +} + +.chest-drawer__panel--left { + background: #e6e6e6; + bottom: 0; + height: calc(var(--drawerHole) * 0.65px); + left: 10px; + transform: translate3d(0, -16px, -2px) rotateY(90deg); + transform-origin: left; + width: calc(var(--depth) * 1px); +} + +.chest-drawer__panel--right { + background: #e6e6e6; + bottom: 0; + height: calc(var(--drawerHole) * 0.65px); + right: 10px; + transform: translate3d(0, -16px, -2px) rotateY(-90deg); + transform-origin: right; + width: calc((var(--depth) - 3) * 1px); +} + +.chest-drawer__panel--bottom { + background: #fff; + bottom: 18px; + height: calc(var(--depth) * 1px); + left: 10px; + transform: rotateX(90deg) translate3d(0, -2px, 0); + transform-origin: bottom center; + width: calc(100% - (2px * 10)); +} + +.chest-drawer__panel--back { + align-items: center; + background: #d9d9d9; + bottom: 16px; + display: flex; + font-family: 'Arial', sans-serif; + font-size: calc(var(--drawerHole) * 0.35px); + font-weight: bold; + height: calc(var(--drawerHole) * 0.65px); + justify-content: center; + left: 10px; + transform: translate3d(0, 0, calc((var(--depth) - 2) * -1px)); + width: calc(100% - (2px * 10)); +} + +.chest-drawer__structure { + height: 100%; + left: 0; + position: absolute; + top: 0; + transform-style: preserve-3d; + transition: transform 0.25s; + width: 100%; +} + +.chest-drawer--top .chest-drawer__panel--back { + color: #111; +} + +.chest-drawer--middle .chest-drawer__panel--back { + color: #111; +} + +.chest-drawer--bottom .chest-drawer__panel--back { + color: #111; +} \ No newline at end of file diff --git "a/20\343\200\201\350\241\250\347\231\275\347\275\221\347\253\231/index.html" "b/20\343\200\201\350\241\250\347\231\275\347\275\221\347\253\231/index.html" new file mode 100644 index 0000000..ec3d85e --- /dev/null +++ "b/20\343\200\201\350\241\250\347\231\275\347\275\221\347\253\231/index.html" @@ -0,0 +1,65 @@ + + + + + +NoSuchKey
+ NoSuchKey
+ NoSuchKey
+ NoSuchKey
+ NoSuchKey
+ NoSuchKey
+ NoSuchKey
+ NoSuchKey
+ 兴盛商场
+您本月需要缴费{{ money }}元
+您目前的余额为{{ mer.balance }}元
+ +{% endblock %}
\ No newline at end of file
diff --git "a/3\343\200\201\347\224\250Python\345\256\236\347\216\260\344\270\200\344\270\252\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237(\351\231\204\346\272\220\347\240\201)/Django+Mysql+Bulma\345\256\236\347\216\260\347\232\204\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237\346\272\220\347\240\201/shopping-mall-master/templates/login.html" "b/3\343\200\201\347\224\250Python\345\256\236\347\216\260\344\270\200\344\270\252\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237(\351\231\204\346\272\220\347\240\201)/Django+Mysql+Bulma\345\256\236\347\216\260\347\232\204\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237\346\272\220\347\240\201/shopping-mall-master/templates/login.html"
new file mode 100644
index 0000000..e51be08
--- /dev/null
+++ "b/3\343\200\201\347\224\250Python\345\256\236\347\216\260\344\270\200\344\270\252\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237(\351\231\204\346\272\220\347\240\201)/Django+Mysql+Bulma\345\256\236\347\216\260\347\232\204\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237\346\272\220\347\240\201/shopping-mall-master/templates/login.html"
@@ -0,0 +1,38 @@
+{% extends 'banner.html' %} {% block title %}
+
+{% endblock %}
\ No newline at end of file
diff --git "a/3\343\200\201\347\224\250Python\345\256\236\347\216\260\344\270\200\344\270\252\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237(\351\231\204\346\272\220\347\240\201)/Django+Mysql+Bulma\345\256\236\347\216\260\347\232\204\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237\346\272\220\347\240\201/shopping-mall-master/templates/login.html" "b/3\343\200\201\347\224\250Python\345\256\236\347\216\260\344\270\200\344\270\252\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237(\351\231\204\346\272\220\347\240\201)/Django+Mysql+Bulma\345\256\236\347\216\260\347\232\204\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237\346\272\220\347\240\201/shopping-mall-master/templates/login.html"
new file mode 100644
index 0000000..e51be08
--- /dev/null
+++ "b/3\343\200\201\347\224\250Python\345\256\236\347\216\260\344\270\200\344\270\252\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237(\351\231\204\346\272\220\347\240\201)/Django+Mysql+Bulma\345\256\236\347\216\260\347\232\204\345\225\206\345\234\272\347\256\241\347\220\206\347\263\273\347\273\237\346\272\220\347\240\201/shopping-mall-master/templates/login.html"
@@ -0,0 +1,38 @@
+{% extends 'banner.html' %} {% block title %}
+欢迎用户:{{ name }}
+ + + {% endif %} +| 商铺地段 | +商铺租金 | +操作 | +
|---|---|---|
| {{ shop.pos }} | +{{ shop.rent.price }} | ++ + 租该商铺 + + | +
 {% else %}
+
{% else %}
+ {{ g.detail }}
+ +| 商户名 | +{{ mer.name }} | +
| 用户名 | +{{ mer.username }} | +
| 联系电话 | +{{ mer.tel }} | +
| 余额 | +{{ mer.balance }} | +
| 我的商铺 | ++ 查看 + | +
| 操作 | ++ + + + + + + + | +
| 商铺名称 | +商铺种类 | +商铺地段 | +本月水费 | +本月电费 | +本月租金 | +
|---|---|---|---|---|---|
| {{ shop.name }} | +{{ shop.type.typename }} | +{{ shop.market.pos }} | +{{ shop.type.paywater.money }} | +{{ shop.type.payelec.money }} | +{{ shop.market.rent.price }} | +